
来自LAION、UC伯克利、HuggingFace等的工作,这篇工作的研究动机也很简单,CLIP 模型在多模态领域展现出了巨大潜力,但原始 CLIP 模型未完全开源,限制了其更广泛的应用和深入研究。OpenCLIP 旨在通过开源的方式,让更多开发者能够无门槛地利用这一先进模型,推动多模态技术在各个领域的应用和发展。

模型架构和原始CLIP无异,下面简单介绍这篇工作中的一些研究规律和实验结果。
01、方法介绍
这篇工作最大的贡献是CLIP中扩展规律研究:通过训练包含数十亿图像文本对的数据集上的CLIP模型,识别出多个下游任务(如零样本分类、检索、线性探测和端到端微调)中的幂律扩展规律。

- 幂律关系:在两个任务中,模型性能随计算量的增加都遵循幂律关系。这意味着性能的提升并不是线性的,而是随着计算量的增加而逐渐减缓。
- 数据量的影响:增加数据量对性能提升有显著影响。特别是在数据量较小的情况下,增加数据量可以显著提高性能。
- 模型规模的影响:更大的模型通常能够从更多的数据中受益,表现出更好的性能。然而,当数据量达到一定规模后,模型规模的增加对性能提升的效果会逐渐减弱。
- 任务差异:在零样本分类任务中,OpenAI的CLIP模型表现更好;而在零样本检索任务中,OpenCLIP模型表现更优。这表明不同的任务可能对模型和数据有不同的需求。
02、模型训练
- 模型规模:选择了几种不同规模的CLIP架构,包括ViT-B/32、ViT-B/16、ViT-L/14、ViT-H/14和ViT-g/14作为视觉编码器。
- 数据规模:使用了LAION-80M(LAION-400M的子集)、LAION-400M和LAION-2B三个不同的数据集。
- 训练样本数量:训练过程中使用的样本数量分别为30亿、130亿和340亿。
03、实验结果
零样本迁移和鲁棒性
模型规模的影响:随着模型规模的增加,零样本分类性能持续提升。下图显示了不同模型规模下的零样本分类准确率,可以看到,模型规模越大,准确率越高。
随着模型规模和数据量的增加,模型在这些鲁棒性基准数据集上的性能也有所提升,尤其是在复杂的噪声和扰动条件下。

- 数据量的影响:增加训练数据量也能显著提高零样本分类性能。表16展示了不同数据量下的VTAB零样本分类结果,可以看出,使用更大的数据集(如LAION-2B)可以显著提升模型在多个任务上的表现。
图像检索
模型规模的影响:随着模型规模的增加,图像检索性能持续提升。下图显示了不同模型规模下的图像检索性能,可以看到,模型规模越大,检索效果越好。

数据量的影响:增加训练数据量也能显著提高图像检索性能。下表展示了不同数据量下的MS-COCO和Flickr30K图像检索结果,可以看出,使用更大的数据集(如LAION-2B)可以显著提升模型的检索性能。



linear probing
模型规模的影响:随着模型规模的增加,线性探测的性能持续提升。图2和图3展示了不同模型规模下的线性探测结果,可以看到,模型规模越大,线性探测的准确率越高。

- 数据量的影响:增加训练数据量也能显著提高线性探测性能。表5展示了不同数据量下的线性探测结果,可以看出,使用更大的数据集(如LAION-2B)可以显著提升模型的线性探测性能。

微调
使用预训练的CLIP模型作为初始化,然后在ImageNet数据集上进行端到端微调
模型规模的影响:随着模型规模的增加,端到端微调的性能持续提升。下图展示了不同模型规模下的端到端微调结果,可以看到,模型规模越大,微调后的准确率越高。
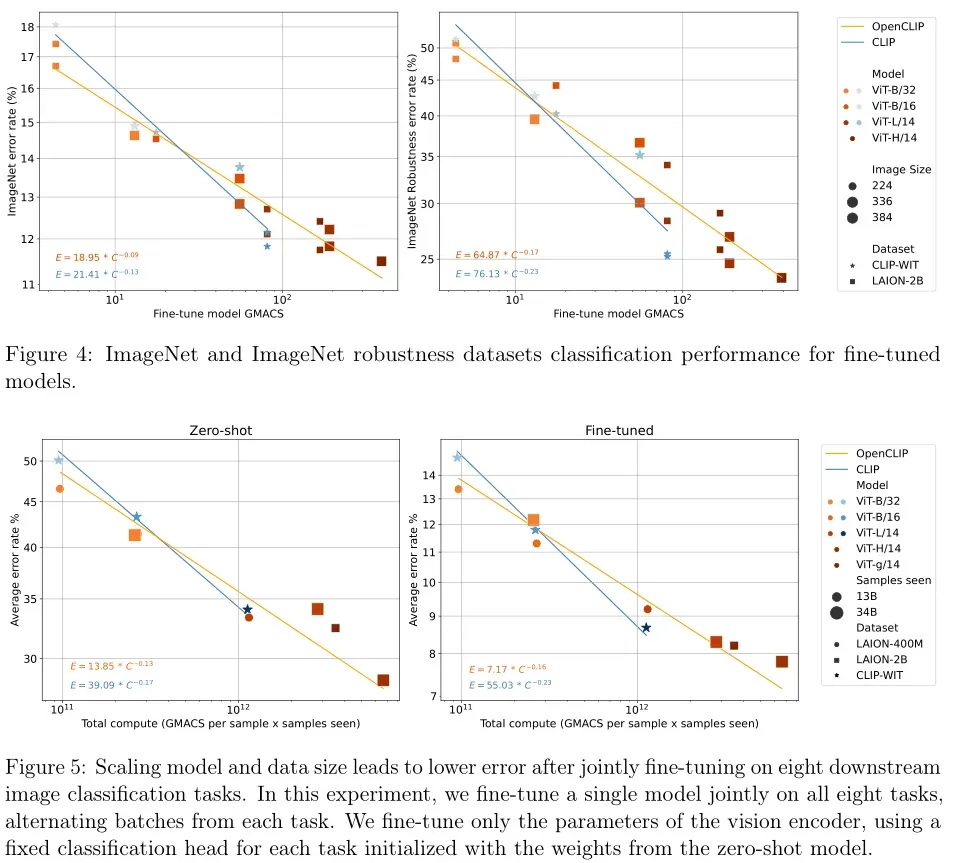
数据量的影响:增加训练数据量也能显著提高端到端微调性能。使用更大的数据集(如LAION-2B)可以显著提升模型的微调性能。
04、总结
作为 CLIP 模型的开源实现,在更大的数据集上进行了训练,具有更多的模型参数,并且提供了更多的模型架构选择,总结出对比图像语言模型的缩放定律,为多模态领域的研究和开发提供了重要资源。其基于 Transformer 架构和对比学习方法,让模型能够有效学习图像与文本之间的关联,推动了多模态技术的发展。


