在人工智能领域,Meta 公司最近推出了 WebSSL 系列模型,这一系列模型的参数规模从3亿到70亿不等,基于纯图像数据进行训练,旨在探索无语言监督的视觉自监督学习(SSL)的巨大潜力。这一新研究为未来的多模态任务带来了新的可能性,也为我们理解视觉表征的学习方式提供了新的视角。
过去,OpenAI 的 CLIP 模型因其在视觉问答(VQA)和文档理解等多模态任务中的优异表现而备受关注。然而,由于数据集的获取复杂性及其规模限制,基于语言的学习方法面临诸多挑战。为了应对这一问题,Meta 决定利用自身的 MetaCLIP 数据集(MC-2B)中的20亿张图像进行训练,完全排除了语言监督的影响。这一策略让研究者们能够深入评估纯视觉自监督学习的表现,而不被数据和模型规模所限制。
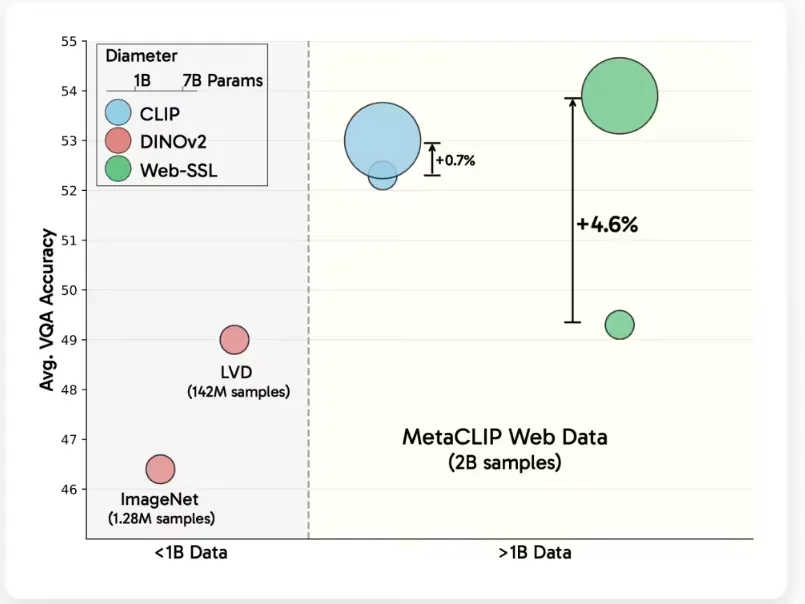
WebSSL 模型采用了两种主要的视觉自监督学习范式:联合嵌入学习(DINOv2)和掩码建模(MAE)。所有模型均使用224×224分辨率的图像进行训练,同时冻结视觉编码器,从而确保结果的差异仅源于预训练策略。这一系列模型在五个容量层级(ViT-1B 至 ViT-7B)上进行训练,并通过 Cambrian-1基准测试进行评估,覆盖了通用视觉理解、知识推理、OCR(光学字符识别)和图表解读等16个 VQA 任务。
实验结果显示,随着模型参数规模的增加,WebSSL 在 VQA 任务中的表现有显著提升,尤其是在 OCR 和图表任务中,其表现甚至超越了 CLIP。此外,通过高分辨率(518px)微调,WebSSL 在文档任务中的表现也大幅提升,缩小了与一些高分辨率模型的差距。

值得一提的是,WebSSL 在无语言监督的情况下,依然展现出与一些预训练语言模型(如 LLaMA-3)良好的对齐性,这意味着大规模视觉模型能够隐式地学习与文本语义相关的特征。这为视觉与语言之间的关系提供了新的思考。
Meta 的 WebSSL 模型不仅在传统的基准测试中表现出色,也为未来无语言学习的研究开辟了新的方向。


