在自动驾驶技术中,车道拓扑提取是实现无地图导航的核心任务之一。它要求系统不仅能检测出车道和交通元素(如交通灯、标志),还要理解它们之间的复杂关系。例如,判断车辆是否可以左转进入某条车道,就需要综合考虑交通规则、车道布局和信号灯状态等多种因素。然而,现有的解决方案存在明显局限性。一方面,密集视觉提示方法虽然准确,但计算成本高昂,且在实时处理中效率低下,难以应用于实际场景。另一方面,神经符号推理方法虽然效率较高,但在处理复杂场景(如交叉路口)时,常常因为缺乏视觉信息而无法做出准确判断。
为了解决这一难题,清华大学与博世中央研究院RIX联合提出了一个创新的解决方案——Chameleon。它通过一种快慢系统交替的神经符号方法,成功平衡了效率与性能,为自动驾驶领域带来了新的突破。
论文链接:https://arxiv.org/pdf/2503.07485
开源地址:https://github.com/XR-Lee/neural-symbolic
引言
在线地图感知是现代自动驾驶中的一个重要课题,它避免了对高成本高精地图的依赖。当前的三维场景理解方法虽然能够有效检测车道和交通元素(如图1所示),但这些实例之间的关系复杂,需要大量标注数据进行监督训练。为此,我们提出了一种基于视觉语言基础模型(VLM)的少样本(few-shot)方法,用于提取车道拓扑。

图1:VLM无法直接解决复杂的三维场景理解任务,例如车道拓扑提取。(a) 一种可能的方法是使用密集视觉提示(如RedCircle),虽然准确但效率低下。(b) 另一种方法是神经符号推理(如NS3D),但这种方法在程序合成时未能有效利用视觉输入,导致在处理复杂边缘情况时效果不佳。(c) 我们提出的Chameleon方法采用快慢交替的设计,其中一个VLM用于合成程序,另一个用于处理边缘情况。
具体而言,我们专注于OpenLane-V2定义的车道拓扑提取任务,即检测车道和交通元素(如交通信号灯和标志),并提取它们之间的关系。这一任务极具挑战性,需要高水平的推理能力,例如判断车辆在交叉路口是否可以驶入某条车道。然而,现有的VLM仍无法直接解决这种复杂的三维场景理解任务。
为解决这一问题,我们结合了两类基于VLM的方法:密集视觉提示和神经符号推理。密集视觉提示(如RedCircle)通过在图像上放置红色圆圈,将复杂推理任务转化为问答(QA)任务。但这种方法会导致大量的QA查询,计算成本高昂且不适合实时应用(如图1-a)。神经符号推理(如NS3D)虽然效率更高,但在程序合成时未能整合视觉信息,无法有效处理复杂边缘情况(如图1-b)。
因此,我们提出了一种名为“Chameleon”的快慢系统交替的神经符号车道拓扑提取器(如图1-c)。它通过VLM合成程序,根据视觉输入定制推理过程,并动态切换快慢系统以平衡效率和性能。此外,我们还提出了一个链式推理(COT)方法,用于识别和处理需要额外推理的边缘情况。

图二:Chameleon架构概览。输入多视图图像后,视觉模型分别生成交通元素和车道线段的检测结果。提出的快速系统利用一个大型视觉语言模型(VLM),以预定义的视觉-文本少样本和文本提示为输入,生成可执行代码以处理视觉模型的预测结果。提出的慢速系统包括一个视觉问答(VQA)API集和一个具有链式推理能力的视觉语言模型(VLM),其中VQA API集中的视觉提示和文本提示是VLM的输入。随后,拓扑推理结果是代码执行结果和VLM输出的组合。
方法
A. 概述
在车道拓扑提取任务中,我们预测一个密集的邻接矩阵,用于表示车道线段和交通元素之间的关系。具体来说,车道线段之间的关系由矩阵 A∈Rm×m 表示,车道线段与交通元素之间的关系由矩阵 A∈Rm×n 表示,其中 m 和 n 分别是车道线段和交通元素的数量。尽管密集视觉提示可以实现高性能,但其高昂的成本、环境影响和低效的推理速度使其不适用于实时应用。因此,我们采用链式推理(Chain-of-Thought, COT)方法,仅对稀疏的边缘情况进行密集视觉提示,从而提高推理效率。
为了高效处理任务,我们设计了快慢系统架构。快速系统使用符号表示处理基本推理任务,适用于简单场景(如直线车道);而慢速系统则针对复杂边缘情况(如交叉路口的密集交通和多种交通元素)进行深度推理。这种架构通过动态切换快慢系统,平衡了效率和性能。

B. 提示
为了执行符号推理,我们使用多种提示来生成符号代码。这些提示包括带有few-shot参考的视觉提示(正例或负例)、API描述和专家规则。
- API提示:API提示定义了生成代码的输入和输出,以及API的输入输出描述,例如用于车道自定位和并行车道搜索的函数等。在我们的实现中,我们还将选定的VQA任务定义为程序合成期间的API。
- 专家规则提示:为了稳定代码生成过程并整合领域专家的先验知识,我们将专家规则添加为程序合成的提示。例如,在TOP lsls任务中,强制执行角度和距离约束。例如,父车道的终点不应与子车道的起点相距过远,以满足驾驶几何约束。在TOP lste任务中,规则规定不允许在交叉路口内存在车道拓扑。
- few-shot提示:在few-shot场景中,我们选择正例和负例,并将它们渲染为相机的透视图。我们还将这些示例的坐标转换为文本,分别作为视觉提示和文本提示。
- VQA提示:对于VQA任务,文本提示由关于语义和空间上下文的简单问题组成。我们还使用链式推理(COT)提示。视觉提示基于预测结果从透视图和鸟瞰图中渲染图像。

图三:Chameleon架构示意图。输入多视图图像和文本提示后,Chameleon实现车道拓扑提取。每个API或密集视觉提示VQA任务表示为一个节点。具有链式推理(Chain-of-Thought, COT)能力的视觉语言模型(VLM)根据输入动态选择需要执行的节点,以推断拓扑结果。
C. 代码执行
对于生成的程序,TOP lsls和TOP lste任务的代码执行过程有所不同。对于TOP lsls任务,使用简单的成对预定义代码框架,VLM根据API描述和给定的提示生成Python代码。此代码以字符串形式生成,然后使用Python的exec函数执行。相比之下,TOP lste任务涉及更多的API调用(如图3所示),因此我们使用OpenAI的函数调用API来管理所需的函数执行。首先,我们提示VLM生成一个链式推理,以解决拓扑提取问题,该问题包含六个步骤(如图3执行模块所示)。这进一步用作文本提示,供VLM合成程序根据视觉输入自适应地跳过某些步骤。某些步骤涉及需要通过密集视觉提示VLM模型处理的边缘情况,因此被送入慢系统。通过总结API结果,系统可以推断出潜在的拓扑对。
D. 密集视觉提示VQA任务
密集视觉提示VQA任务是慢系统的核心API,特别是在开放场景拓扑推理的互操作过程中。为了测试VLM模型的能力,我们创建了几个基本的VQA任务。如表II所示,我们关注四个不同的任务。在“左或右”任务中,以鸟瞰图(BEV)的形式呈现两条车道线段。模型需要执行三类分类,选择左侧、右侧或无关系。对于“是否在交叉路口”任务,以马赛克形式显示单条车道,左侧为鸟瞰图(BEV),右侧为前方透视图(PV)。模型需要判断该车道线段是否在交叉路口内。在“邻接性”任务中,给出两条车道线段,模型需要判断它们是否相邻。最后,在“向量”任务中,模型需要评估两条渲染的向量箭头的方向是否匹配。
实验
A. 实验设置
我们在OpenLane-V2官方验证数据集上评估了Chameleon方法,该数据集提供了车道线段和交通元素之间的拓扑注释。此外,我们手动标注了500个样本,涵盖四个密集视觉提示VQA子任务,用于评估性能指标。这些数据集不仅支持车道拓扑提取任务,还适用于其他自动驾驶场景。
在评估指标方面,我们报告车道线段检测和交通元素检测的平均精度均值(mAP)。对于拓扑任务,采用OpenLane-V2官方指标TOPlsls(车道线段间拓扑mAP)和TOPlste(车道线段与交通元素间拓扑mAP)。对于VQA分类问题,由于正负样本在标注时保持平衡,我们使用准确率(Accuracy)作为评估指标。


B. 实现细节
我们将Chameleon方法应用于自定义基线,并进行了实验。基线方法结合了SMERF的SD编码和融合模块,使用LanesegNet框架检测车道线段,并通过DETR实现2D交通元素检测,同时并行训练TopoMLP以预测拓扑关系。为了进一步提升性能,我们还设计了一个增强基线(“Powerful Baseline”),引入了StreamMapNet的时间信息,使用更大的Vovnet作为骨干网络,并采用YOLOv8进行交通元素检测。在少样本学习场景中,我们采用3-shot配置,包含三个帧及其注释作为参考。
对于视觉语言模型(VLM),我们使用了GPT-4的官方API(包括GPT-4-vision-preview和GPT-4o)以及LLaVA-v1.5-13b-full ft-1e权重。此外,我们还进行了VQA基准测试,使用基于ResNet18的MLP分类模型,数据集按3:1比例分为训练集和测试集,采用Adam优化器和交叉熵损失函数进行20个周期的训练。
C. 定量和定性结果
与最新方法的比较:在本节中,我们将提出的少样本方法与OpenLane-V2验证集上的最新监督方法进行了比较。表I显示了与LaneSegNet、TopoLogic和MapVision等方法的比较结果。
我们的方法使用了两个不同的基线,每个基线使用不同的骨干网络。基线基于LanesegNet和TopoMLP实现,并结合了SMERF中的SD编码和融合过程。如表所示,我们的方法在few-shot设置中实现了与监督基线相当的性能,甚至在TOPlste任务中略微超过了全监督模型。总体而言,我们的方法在仅使用少样本的情况下表现出显著的竞争力。

图四:TopoMLP和我们的方法(Chameleon)在OpenLane-V2验证数据集上的定性结果对比。(a) 车辆刚刚通过交叉路口。(b) 前方有一个左转交通灯。(c) 地面车道标有直行标志。(d) 车辆行驶在单向右转车道上。所选场景均为边缘情况,需要通过密集视觉提示进行进一步推理。每个子图均包含鸟瞰图(BEV)和前视图(PV)。蓝色线条表示车道线段检测结果,绿色线条表示车道与交通元素之间的真正例(ls-te),粉色线条表示车道与交通元素之间的假正例(ls-te)。当车辆刚刚通过交叉路口时(图4-a),车辆正上方的绿灯与交叉路口前方的车道没有拓扑关系。我们的方法(Chameleon)理解了绿灯与车道之间的空间关系,从而做出了正确的判断,而TopoMLP则相反。在图4-b中,左转交通灯仅与最左侧车道存在拓扑连接。与TopoMLP不同,我们的方法正确地忽略了与右侧车道的关系。地面车道标有直行标志(图4-c),因此该标志仅与其自身车道和连接车道相关,而不是其他平行车道。我们的方法做到了这一点,而TopoMLP没有做到。车辆行驶在单向右转车道上(图4-d),控制直行交通的两侧绿灯不影响车辆。我们的解决方案正确地判断了绿灯与车道之间不存在拓扑关系。
不同VLM方法的VQA比较:由于其通用性,VQA与各种VLM兼容。表II比较了不同VLM在四个任务上的性能。在这些任务中,我们发现GPT-4的性能与监督分类器模型相当,而LLaVA在语义和空间理解任务中表现较差。

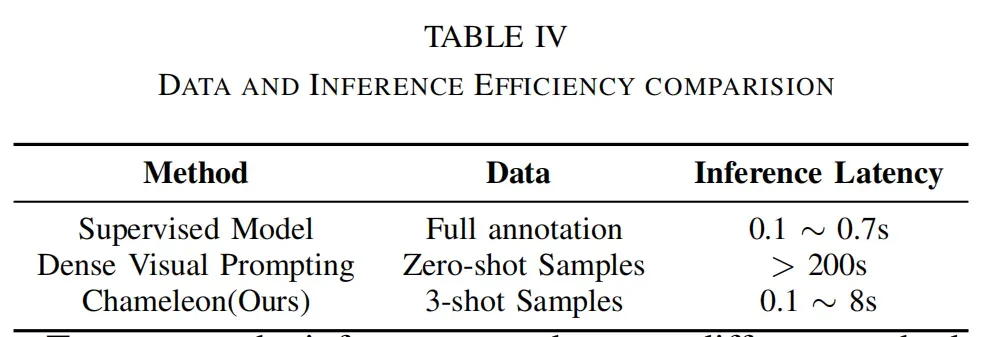
数据和推理效率比较:为了比较不同方法之间的推理成本,我们在RTX 4080 GPU上测试了LLaVA的平均VQA任务延迟。平均VQA延迟约为1447毫秒。在我们的实验中,每帧平均执行6次VQA,导致慢速系统的延迟为8.7秒/帧。TopoMLP的延迟根据不同的骨干网络和图像分辨率而变化,范围从140毫秒到700毫秒。密集视觉提示的延迟是基于20×20矩阵的逐个VQA计算得出的,结果为每帧超过200秒。详细信息总结在表IV中。
定性结果:为了更直观地展示我们算法的性能,我们还提供了OpenLane-V2验证数据集上预测的ls-ls关系和ls-te关系的定性可视化结果。所有比较的场景均为边缘情况,每个子图均包含鸟瞰图和前视图。蓝色线条表示车道线段检测结果,绿色线条表示ls-te真正例,粉色线条表示ls-te假正例。
当车辆刚刚通过交叉路口时(图4-a),车辆正上方的绿灯与交叉路口前方的车道没有拓扑关系。我们的方法(Chameleon)理解了绿灯与车道之间的空间关系,从而做出了正确的判断,而TopoMLP则相反。在图4-b中,左转交通灯仅与最左侧车道存在拓扑连接。与TopoMLP不同,我们的方法正确地忽略了与右侧车道的关系。地面车道标有直行标志(图4-c),因此该标志仅与其自身车道和连接车道相关,而不是其他平行车道。我们的方法做到了这一点,而TopoMLP没有做到。车辆行驶在单向右转车道上(图4-d),控制直行交通的两侧绿灯不影响车辆。我们的解决方案正确地判断了绿灯与车道之间不存在拓扑关系。

D. 消融研究
我们在OpenLane-V2验证集上对TOPlsls任务进行了消融研究,以评估我们框架中每个组件的有效性。结果如表V所示。“提示到符号”指的是仅提供API提示的基本神经符号推理。由于生成代码的不稳定性,我们报告了三次符号推理结果的平均值作为最终性能。“专家规则”指的是将专家观察结果纳入提示。对于少样本示例,我们引入了三个正例和三个负例以改进生成的程序。
结论
本文介绍了一种名为“Chameleon”的新方法,该方法结合了密集视觉提示和神经符号推理,利用视觉语言基础模型(VLM)以few-shot的方式提取车道拓扑。Chameleon通过整合视觉信息来合成程序,针对特定场景定制处理过程,并通过密集视觉提示高效地处理边缘情况。通过平衡计算效率和高性能,Chameleon适用于实时机器人应用,并展示了将视觉输入整合到复杂三维场景任务程序合成中的潜力。未来的工作可以探索将这种方法扩展到其他自动驾驶领域。


