基于逐步生成解决方案的大语言模型(LLMs)训练范式在人工智能领域获得了广泛关注,并已发展成为行业内的主流方法之一。
例如,OpenAI 在其「12 Days of OpenAI」直播系列的第二日推出了针对 O1 模型的强化微调(Reinforcement Fine-Tuning,RFT),进一步推动了 AI 定制化的发展[1]。RFT/ReFT[2] 的一个关键组成部分是使用思维链(Chain-of-Thought,CoT)注释[3] 进行监督微调(Supervised Fine-Tuning,SFT)。在 DeepSeek-R1 模型[4] 中,引入了少量长 CoT 冷启动数据,以调整模型作为初始强化学习的代理。
然而,为了全面理解采用 CoT 训练的策略,需要解决两个关键问题:
- Q1:与无 CoT 训练相比,采用 CoT 训练有哪些优势?
- Q2:如果存在优势,显式 CoT 训练的潜在机制是什么?
由于实际训练过程中涉及众多因素,分析显式 CoT 训练的优势及其潜在机制面临显著挑战。为此,我们利用清晰且可控的数据分布进行了详细分析,并揭示了以下有趣现象:
- CoT 训练的优势
(i)与无 CoT 训练相比,CoT 训练显著增强了推理泛化能力,将其从仅适用于分布内(in-distribution, ID)场景扩展到 ID 和分布外(out-of-distribution, OOD)场景(表明系统性泛化),同时加速了收敛速度(图 1)。

图表 1: 模型在优化过程中对训练和测试两跳推理事实的准确率。
(ii)即使 CoT 训练中包含一定范围的错误推理步骤,它仍能使模型学习推理模式,从而实现系统性泛化(图 4 和图 5)。这表明数据质量比方法本身更为重要。训练的主要瓶颈在于收集复杂的长 CoT 解决方案,而推理步骤中存在少量的错误是可以接受的。
- CoT 训练的内部机制
(i)数据分布的关键因素(如比例 λ 和模式 pattern)在形成模型的系统性泛化中起着决定性作用。换句话说,在 CoT 训练中仅接触过两跳数据的模型无法直接泛化到三跳情况,它需要接触过相关模式。
(ii)通过 logit lens 和 causal tracing 实验,我们发现 CoT 训练(基于两跳事实)将推理步骤内化到模型中,形成一个两阶段的泛化电路。推理电路的阶段数量与训练过程中显式推理步骤的数量相匹配。
我们进一步将分析扩展到推理过程中存在错误的训练数据分布,并验证了这些见解在现实数据上对更复杂架构仍然有效。
据我们所知,我们的研究首次在可控制的实验中探索了 CoT 训练的优势,并提供了基于电路的 CoT 训练机制解释。这些发现为 CoT 以及 LLMs 实现稳健泛化的调优策略提供了宝贵的见解。

- 论文标题:Unveiling the Mechanisms of Explicit CoT Training: How Chain-of-Thought Enhances Reasoning Generalization
- 论文链接:https://arxiv.org/abs/2502.04667
一、预备知识与定义
本部分介绍研究使用的符号定义,具体如下:
原子与多跳事实:研究使用三元组 来表示原子(一跳)事实,并基于原子事实和连接规则来表示两跳事实以及多跳事实。
来表示原子(一跳)事实,并基于原子事实和连接规则来表示两跳事实以及多跳事实。

训练数据:研究使用的训练数据包括所有的原子(一跳)事实(即 ),以及分布内(ID)的两跳事实(即
),以及分布内(ID)的两跳事实(即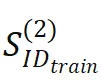 )。其中记 | 两跳事实 |:| 原子事实 |= λ。
)。其中记 | 两跳事实 |:| 原子事实 |= λ。

训练方式:对于原子(一跳)事实,模型的训练和评估通过预测最终尾实体来完成。对于两跳事实,考虑是否使用 CoT 注释进行训练。
(1) Training without CoT:模型输入 ,预测目标只有最终尾实体
,预测目标只有最终尾实体 ;
;
(2) Training with CoT:模型输入 ,预测桥接实体
,预测桥接实体 和最终尾实体
和最终尾实体 。
。

评估:为更好地评估模型的泛化能力,我们从分布内(ID)和分布外(OOD)两个维度进行性能评估。
(1)分布内泛化旨在通过评估模型完成未见过的两跳事实 的能力,判断模型是否正确学习了潜在模式。
的能力,判断模型是否正确学习了潜在模式。
(2)分布外泛化则用于评估模型获得的系统性能力,即模型将学习到的模式应用于不同分布知识的能力,这是通过在 事实上测试模型来实现的。若模型在分布内数据上表现良好,可能仅表明其记忆或学习了训练数据中的模式。然而,在分布外数据上的优异表现则表明模型确实掌握了潜在模式,因为训练集仅包含原子事实
事实上测试模型来实现的。若模型在分布内数据上表现良好,可能仅表明其记忆或学习了训练数据中的模式。然而,在分布外数据上的优异表现则表明模型确实掌握了潜在模式,因为训练集仅包含原子事实 ,而不包含
,而不包含 。
。
二、系统性组合泛化
本研究聚焦于模型的组合能力,即模型需要将不同事实片段「串联」起来的能力。尽管显式的推理步骤表述(如思维链推理)能够提升任务表现 [4-8],但这些方法在大规模(预)训练阶段并不可行,而该阶段正是模型核心能力形成的关键时期 [9-10]。已有研究对基于 Transformer 的语言模型是否能够执行隐式组合进行了广泛探讨,但均得出了否定结论 [11-12]。
具体而言,存在显著的「组合性鸿沟」[11],即模型虽然掌握了所有基础事实却无法进行有效组合的情况,这种现象在不同大语言模型中普遍存在,且不会随模型规模扩大而减弱。
更准确地说,Wang 等人 [13] 的研究表明,Transformer 模型能够在同分布泛化中学习隐式推理,但在跨分布泛化中则表现欠佳(如图 1 左所示)。
这自然引出一个问题:如果在训练过程中使用显式推理步骤,模型的泛化能力将受到何种影响?(即回答 Q1:与无思维链训练相比,基于思维链的训练具有哪些优势?)
思维链训练显著提升推理泛化能力
如图 1 所示,我们展示了模型在训练和测试两跳事实上的准确率随优化过程的变化,其中 λ = 7.2。
(1)Training without CoT(图 1 左)。我们观察到了与 Wang 等人 [13] 相同的现象(称为顿悟现象 [14]),即模型能够较好地泛化到分布内测试样本 ,但高性能只有在经过大量训练后才能实现,远超过过拟合点。此外,即使经过数百万次优化步骤的训练,仍未观察到分布外泛化(
,但高性能只有在经过大量训练后才能实现,远超过过拟合点。此外,即使经过数百万次优化步骤的训练,仍未观察到分布外泛化( )的迹象,这表明这是一种缺乏系统性的延迟泛化现象。模型可能只是记忆或学习了训练数据中的模式。
)的迹象,这表明这是一种缺乏系统性的延迟泛化现象。模型可能只是记忆或学习了训练数据中的模式。
(2)Training with CoT(图 1 右)。使用思维链标注后,模型在训练集上的收敛速度加快,且在训练过程中更早地实现了较高的测试性能,特别是在分布内测试样本上。模型在大约 4,000 次优化步骤后,在同分布测试集 上的准确率就达到了接近完美的水平,表明与无思维链训练相比,泛化能力得到了显著提升。分布外泛化(
上的准确率就达到了接近完美的水平,表明与无思维链训练相比,泛化能力得到了显著提升。分布外泛化( )也显示出明显改善,这突出表明思维链提示训练不仅在分布内泛化方面,而且在分布外泛化方面都发挥着关键作用,尽管效果程度有所不同。
)也显示出明显改善,这突出表明思维链提示训练不仅在分布内泛化方面,而且在分布外泛化方面都发挥着关键作用,尽管效果程度有所不同。

关键影响因素探究
研究进一步开展了消融实验,以评估不同因素在思维链训练中的影响。

图表 2: 分布外测试集上的推理泛化速度。
适当的 λ 值能够加速模型收敛。图 2(左)展示了不同 λ 值下的分布外测试准确率。可以看出,λ 值与泛化速度存在强相关性。更有趣的是,较小的 λ 值能够加速由思维链训练带来的分布外泛化能力提升,从而减少对长时间训练的需求。然而,λ 值并非越小越好,因为过小的 λ 值可能导致模型无法学习相关规则。
不同模型规模 / 层数和训练集大小的影响。我们在模型层数∈{2,4,8} 和 λ∈{3.6,7.2,12.6} 的条件下进行实验。总体而言,可以观察到扩大模型规模并不会从根本上改变其泛化行为,主要趋势是较大的模型能够在更少的优化步骤中收敛。关于训练集大小(|E|)的影响,我们的结果与 [13] 一致:当固定 λ 值时,训练集大小不会对模型的泛化能力产生本质影响。
两跳到多跳分析
在本部分中,研究将重点转向多跳场景:在思维链训练阶段仅接触过两跳事实的模型,能否泛化到三跳事实?
在思维链训练中,我们仅使用单跳 / 两跳事实,并测试模型是否能够泛化到三跳事实的推理(这里研究使用 来表示三跳事实)。
来表示三跳事实)。
结果:在思维链训练中仅接触过两跳数据的模型无法直接泛化到三跳场景。然而,当训练集中加入一定量的三跳数据后,模型能够快速实现泛化(前提是模型需要接触过相关模式)。另一方面,当我们人为地将一个三跳事实拆分为两个两跳事实进行测试时,模型也能够有效泛化。换句话说,我们分别测试 预测
预测 和
和 预测
预测 ,当两者都正确时,我们认为
,当两者都正确时,我们认为 预测
预测 是正确的。这些发现与 [15] 结果一致:思维链与重现训练集中出现的推理模式有关。
是正确的。这些发现与 [15] 结果一致:思维链与重现训练集中出现的推理模式有关。

总结:至此,我们已经证明在受控实验中引入显式思维链训练能够显著提升推理泛化能力,使其从仅限分布内泛化扩展到同时涵盖分布内和分布外泛化。数据分布的关键因素(如比例和模式)在形成模型的系统性泛化能力中起着重要作用。然而,驱动这些改进的内部机制仍不明确,我们将进一步探讨(回答 Q2:如果存在优势,显式思维链训练的潜在机制是什么?)。

图表 3: 两跳事实训练对应的两阶段泛化电路(模型层数:8)。
三、两阶段泛化电路
研究通过两种主流方法分析模型在泛化过程中的内部工作机制:logit lens [16] 和 causal tracing [17],本部分研究使用 表示两跳推理。
表示两跳推理。
图 3 展示了发现的泛化电路,该电路代表了 8 层模型在实现两跳分布外(OOD)泛化后的因果计算路径。具体而言,我们识别出一个高度可解释的因果图,该图由第 0 层、第 l 层和第 8 层的状态组成,其中弱节点和连接已被剪枝(If perturbing a node does not alter the target state (top-1 token through the logit lens), we prune the node)。
(1)在第一跳阶段,第 l 层将电路分为上下两部分:下部从输入 中检索第一跳事实,并将桥接实体
中检索第一跳事实,并将桥接实体 存储在状态
存储在状态 中;上部通过残差连接将的信息传递到输出状态(其中
中;上部通过残差连接将的信息传递到输出状态(其中 表示对应位置的激活)。由于数据分布可控,l 层可以精确定位(对于 ID 为第 3 层,对于 OOD 为第 5 层)。
表示对应位置的激活)。由于数据分布可控,l 层可以精确定位(对于 ID 为第 3 层,对于 OOD 为第 5 层)。
(2)在第二跳阶段,自回归模型使用第一跳阶段生成的 。该阶段省略了
。该阶段省略了 ,并从输入
,并从输入 处理第二跳,将尾实体
处理第二跳,将尾实体 存储到输出状态
存储到输出状态 中。
中。

系统性泛化解释
(1)两阶段泛化电路表明,使用思维链训练可以将推理步骤内化到模型中。这也解释了为什么模型在思维链训练下能够在跨分布测试数据上表现出良好的泛化能力。
(2)该电路由两个阶段组成,与训练期间模型中的显式推理步骤相一致。因此,模型在思维链训练期间仅接触两跳数据时无法在测试阶段直接泛化到三跳场景。
四、更普适的分析
总体而言,我们目前的研究为通过受控数据分布上的思维链训练来深入理解和增强 Transformer 的泛化能力铺平了道路。然而,现实世界中的训练数据分布往往更为复杂。在本部分中,我们将分析扩展到推理过程中存在错误的分布,并展示思维链训练能提高模型的泛化能力的结论在更复杂的场景中仍然成立。
数据分布带噪
方法:我们旨在分析通过思维链训练获得的系统性泛化能力在噪声训练数据下的鲁棒性。我们通过随机选择一个有效实体向 引入噪声(真实训练目标为
引入噪声(真实训练目标为 ):
):
(1)仅第二跳有噪声,即 ;
;
(2)两跳均有噪声,即 。
。
需要注意的是,噪声比例用 ξ 表示,我们将探讨不同 ξ 值的影响。

图表 4: 仅第二跳噪声对分布内和分布外的影响。

图表 5: 模型在不同噪声比例(两跳均有噪声)下对训练和测试两跳推理事实的准确率。
结果:我们针对两种情况分析了不同的 ξ(噪声比例)候选集:仅第二跳有噪声时为 {0.05, 0.2, 0.4, 0.6, 0.8},两跳均有噪声时为 {0.05, 0.1, 0.2, 0.4}。比较结果如下:
(1)图 4 清晰地展示了仅第二跳噪声对分布内和分布外泛化的影响。总体而言,在思维链训练条件下,模型仍能够从噪声训练数据中实现系统性泛化,但其泛化能力随着噪声比例的增加而降低。
更具体地说,随着训练的进行,分布外泛化最初保持不变,然后增加,而分布内泛化先增加后减少。分布内泛化的减少与分布外泛化的增加相对应。
然而,随着噪声比例的增加,分布内和分布外泛化的最终性能都会下降。特别是当噪声比例(ξ < 0.2)相对较小时,模型几乎不受影响,这展示了思维链训练的鲁棒性。
此外,我们同样检查了泛化电路。由于我们仅在第二跳添加噪声,第一跳阶段的电路学习得相对较好,而第二跳阶段的电路受噪声影响更大。
(2)图 5 展示了在两跳噪声 ξ 值为 0.05、0.1、0.2 和 0.4 时的结果比较。与仅在第二跳添加噪声相比,在两跳都添加噪声对模型泛化的抑制效果要强得多。大于 0.2 的噪声比例足以几乎消除分布内和分布外泛化能力。
总而言之,即使在训练数据存在噪声的情况下,当噪声在一定范围内时,思维链训练仍能使模型实现系统性泛化。特别是当噪声比例较小时,这些噪声数据仍能帮助模型学习泛化电路。

五、讨论
总结
本文通过在受控和可解释的环境中展示系统性组合泛化如何通过显式思维链(CoT)训练在 Transformer 中产生,揭示了思维链训练的核心机制。具体而言:
(1)与无思维链训练相比,思维链训练显著增强了推理泛化能力,使其从仅限分布内(ID)泛化扩展到同时涵盖分布内和分布外(OOD)场景。
(2)通过 logit lens 和 causal tracing 实验,我们发现思维链训练(使用两跳事实)将推理步骤内化到 Transformer 中,形成了一个两阶段泛化电路。然而,模型的推理能力受训练数据复杂性的限制,因为它难以从两跳情况泛化到三跳情况。这表明思维链推理主要是重现了训练集中存在的推理模式。
(3)我们进一步将分析扩展到推理过程中存在错误的训练数据分布,证明当噪声保持在一定范围内时,思维链训练仍能使模型实现系统性泛化,此类噪声数据的结构或许有助于泛化电路的形成。
有趣的是,我们的工作还突出了思维链训练的瓶颈:训练数据分布(比例 λ 和模式)在引导模型实现泛化电路方面起着关键作用。模型需要在训练过程中接触过相关模式(特别是思维链步骤的数量)。
这可能解释了为什么 DeepSeek-R1 [4] 在冷启动阶段构建和收集少量长思维链数据来微调模型。我们的发现为调整大语言模型(LLMs)以实现稳健泛化的策略提供了关键见解。
不足与未来展望
(1)尽管我们的自下而上的研究为实际应用提供了宝贵的见解,但我们工作的一个关键局限是实验和分析基于合成数据,这可能无法完全捕捉现实世界数据集和任务的复杂性。虽然我们的一些结论也在 Llama2-7B [18] 等模型中得到了验证,但有必要在更广泛的模型上进行进一步验证,以弥合我们的理论理解与实际应用之间的差距。
(2)我们的分析目前仅限于使用自然语言。未来,我们旨在探索大型语言模型在无限制潜在空间中的推理潜力,特别是通过训练大型语言模型在连续潜在空间中进行推理 [19] 等方法。
(3)最近的一种方法,「backward lens」[20],将语言模型的梯度投影到词汇空间,以捕捉反向信息流。这为我们完善思维链训练的潜在机制分析提供了一个新的视角。
作者介绍
刘勇,中国人民大学,长聘副教授,博士生导师,国家级高层次青年人才。长期从事机器学习基础理论研究,共发表论文 100 余篇,其中以第一作者 / 通讯作者发表顶级期刊和会议论文近 50 篇,涵盖机器学习领域顶级期刊 JMLR、IEEE TPAMI、Artificial Intelligence 和顶级会议 ICML、NeurIPS 等。获中国人民大学「杰出学者」、中国科学院「青年创新促进会」成员、中国科学院信息工程研究所「引进优青」等称号。主持国家自然科学面上 / 基金青年、北京市面上项目、中科院基础前沿科学研究计划、腾讯犀牛鸟基金、CCF - 华为胡杨林基金等项目。
姚鑫浩,中国人民大学高瓴人工智能学院博士研究生,本科毕业于中国人民大学高瓴人工智能学院。当前主要研究方向包括大模型推理与机器学习理论。


