话说在计算机科学领域,将那些结构复杂的文档变成规整的数据,一直是个让人头疼的“老大难”问题。以前的“土办法”,要么是各种模型“组团出道”,搞出一套复杂的流程,要么就得祭出“巨无霸”级别的多模态模型,虽然看起来很厉害,但动不动就“幻觉”,还特别“烧钱”。

不过最近由IBM和Hugging Face联手推出的SmolDocling,只有256M参数的开源视觉-语言模型(VLM),目标非常明确,就是要端到端地解决多模态文档转换的任务。
SmolDocling的独门秘籍
SmolDocling最让人称道的地方,就是它的“小巧玲珑”和“一身绝技”。与那些动辄几十亿、几百亿参数的“大模型”不同,SmolDocling仅仅256兆的体量,简直是模型界的“轻骑兵”,显著降低了计算复杂性和资源需求。更厉害的是,它能够通过单个模型处理整个页面,这一下就把传统方法中复杂的处理流程给简化了。
当然,“个子小”并不代表实力弱。SmolDocling还拥有一项“独门武器”——DocTags,这是一种通用的标记格式,能够以高度紧凑和清晰的方式精确捕捉页面元素、它们的结构和空间上下文。你可以把它想象成给文档里的每个元素都贴上了清晰的“标签”,让机器能够准确理解文档的内在逻辑。
SmolDocling的架构基于Hugging Face的SmolVLM-256M,通过优化的tokenization和激进的视觉特征压缩方法,实现了计算复杂性的显著降低。它的核心优势在于创新的DocTags格式,能够清晰地分离文档布局、文本内容以及表格、公式、代码片段和图表等视觉信息。为了更高效地训练,SmolDocling还采用了课程学习的方法,先“冻结”视觉编码器,然后逐步使用更丰富的数据集进行微调,以增强不同文档元素之间的视觉语义对齐。更令人惊喜的是,得益于其高效性,SmolDocling处理整个文档页面的速度非常快,在消费级GPU上平均每页仅需0.35秒,且仅消耗不到500MB的显存。
“小模型也能打败“巨无霸”
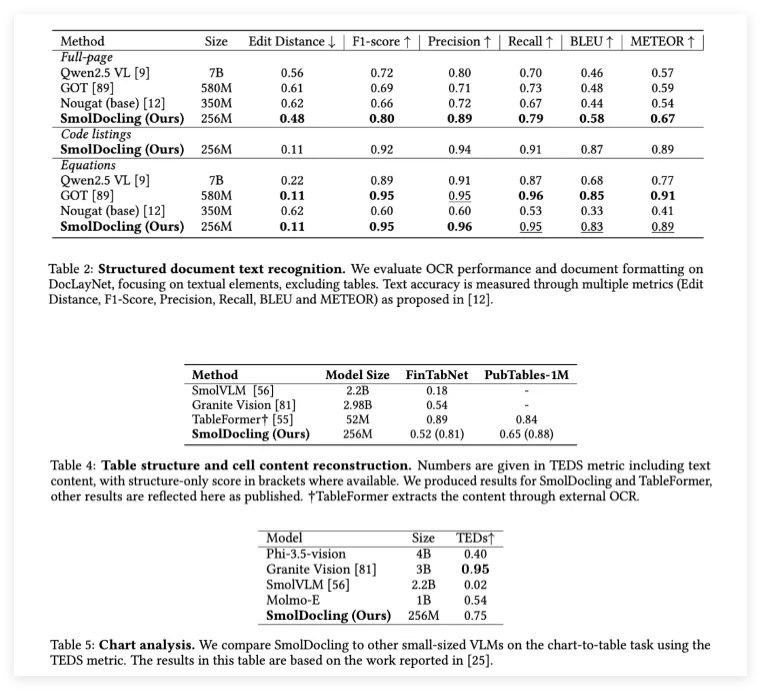
事实胜于雄辩,SmolDocling在性能测试中用实力证明了自己并非“花架子”。在涉及各种文档转换任务的综合基准测试中,SmolDocling的表现显著优于许多体量更大的竞争模型。例如,在全页文档OCR任务中,与拥有70亿参数的Qwen2.5VL和3.5亿参数的Nougat相比,SmolDocling取得了明显更高的准确率,其编辑距离(0.48)更低,F1分数(0.80)更高。
在公式转录方面,SmolDocling也达到了0.95的F1分数,与最先进的模型如GOT不相上下。更令人称赞的是,SmolDocling还在代码片段识别方面树立了新的标杆,精确率和召回率分别高达0.94和0.91。这简直是“小个子,大力气”,在各个关键领域都展现出了惊人的实力!
“十八般武艺”:复杂文档也能轻松搞定
SmolDocling与其他文档OCR解决方案的不同之处在于,它能够处理文档中的各种复杂元素,包括代码、图表、公式和各种不同的布局。它的能力不仅限于常见的科学论文,还能可靠地处理专利、表格和商业文档。
通过DocTags提供全面的结构化元数据,SmolDocling消除了HTML或Markdown等格式固有的歧义,从而提高了文档转换的下游可用性。其紧凑的体积还使其能够以极低的资源需求进行大规模的批量处理,为大规模部署提供了经济高效的解决方案。这意味着,以后企业在处理海量复杂文档时,再也不用为高昂的计算成本和复杂的流程而烦恼了。
总而言之,SmolDocling的发布代表了文档转换技术的重大突破。它有力地证明了,紧凑型模型不仅能够与大型基础模型竞争,而且在关键任务中还能显著超越它们。
研究人员成功地展示了,通过有针对性的训练、创新的数据增强和像DocTags这样的新型标记格式,可以克服传统上与模型大小和复杂性相关的局限性。SmolDocling的开源不仅为OCR技术树立了新的效率和多功能性标准,还通过开放的数据集和高效紧凑的模型架构,为社区提供了一份宝贵的资源。


