本文经AIGC Studio公众号授权转载,转载请联系出处。
今天给大家介绍的是一个高保真实时人脸编辑方法PersonaMagic,通过分阶段的文本条件调节和动态嵌入学习来优化人脸定制。该技术利用时序动态的交叉注意力机制,能够在不同阶段有效捕捉人脸特征,从而在生成个性化图像时最大程度地保留身份信息。通过对比实验,PersonaMagic在定量和定性评估中均优于现有的最先进方法,展现出其在多种场景和风格下的灵活性与鲁棒性。
 PersonaMagic 可根据用户提供的肖像无缝生成新角色、风格或场景的图像。通过通过串联平衡策略学习阶段调节嵌入,该方法可以准确捕捉和表示看不见的概念,忠实地创建与提供的提示相符的角色,同时最大限度地减少身份扭曲。
PersonaMagic 可根据用户提供的肖像无缝生成新角色、风格或场景的图像。通过通过串联平衡策略学习阶段调节嵌入,该方法可以准确捕捉和表示看不见的概念,忠实地创建与提供的提示相符的角色,同时最大限度地减少身份扭曲。
相关链接
- 论文:http://arxiv.org/abs/2412.15674v1
- 代码:https://github.com/xzhe-Vision/PersonaMagic
论文介绍
 PersonaMagic:采用串联平衡的阶段调节高保真面部定制
PersonaMagic:采用串联平衡的阶段调节高保真面部定制
摘要
个性化图像生成在将内容适应新概念方面取得了重大进展。然而,仍然存在一个持续的挑战:平衡看不见的概念的准确重建与根据提示进行编辑的需求,特别是在处理面部特征的复杂细微差别时。在本研究中,我们深入研究了文本到图像调节过程的时间动态,强调了阶段划分在引入新概念方面的关键作用。我们提出了 PersonaMagic,这是一种专为高保真面部定制而设计的阶段调节生成技术。使用一个简单的 MLP 网络,我们的方法在特定的时间步长间隔内学习一系列嵌入来捕捉面部概念。此外,我们开发了一种串联平衡机制,可以调整文本编码器中的自我注意响应,平衡文本描述和身份保存,从而改善这两个领域。大量实验证实了 PersonaMagic 在定性和定量评估方面都优于最先进的方法。此外,它的稳健性和灵活性在非面部领域得到了验证,并且它还可以作为增强预训练个性化模型性能的有价值的插件。
方法
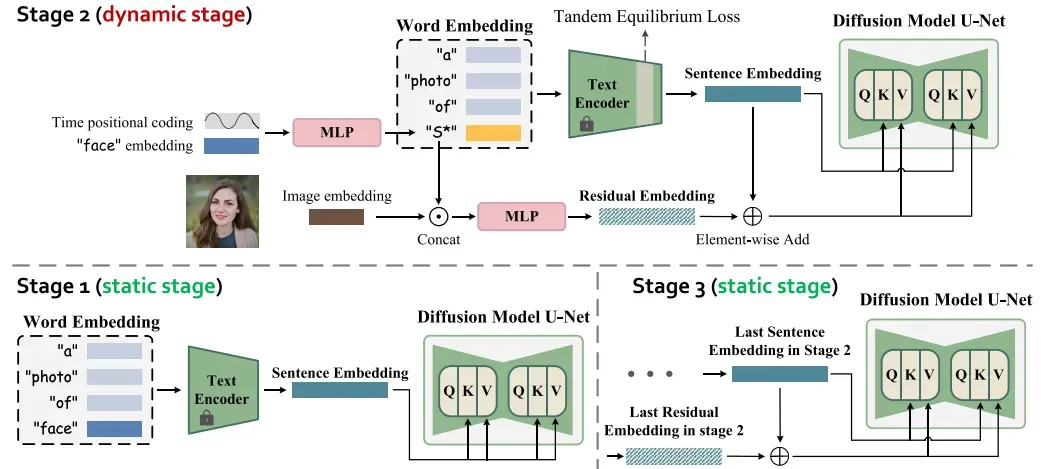 流程概述。 给定一张图像,我们在动态阶段学习一系列嵌入以有效地捕获身份信息,同时在静态阶段使用固定嵌入。提出的 TE 策略应用于文本编码器,确保个性化结果与文本描述进一步对齐。
流程概述。 给定一张图像,我们在动态阶段学习一系列嵌入以有效地捕获身份信息,同时在静态阶段使用固定嵌入。提出的 TE 策略应用于文本编码器,确保个性化结果与文本描述进一步对齐。

被忽视的语义导致注意力图不理想。注意力权重标注在交叉注意力图的左下角。
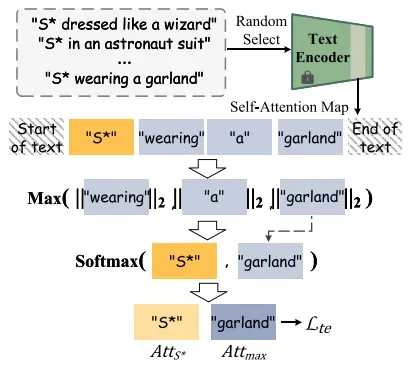
所提出的串联平衡的图示。
结果

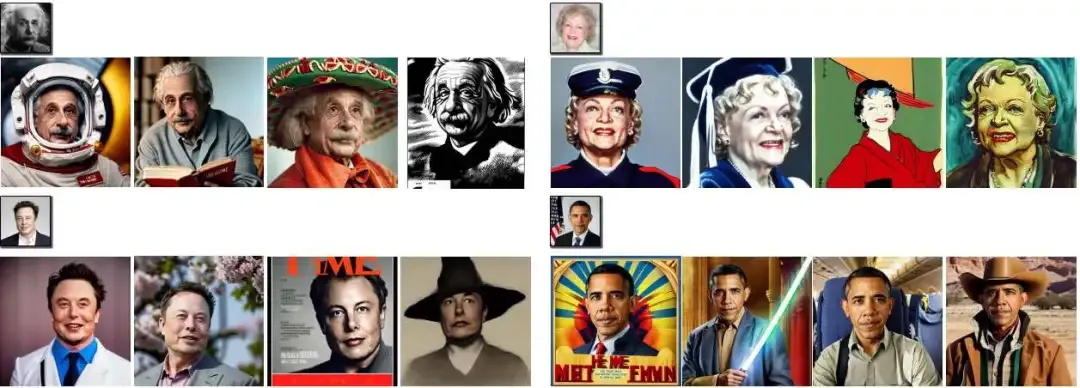
与最先进的方法对名人的定性比较。

与非名人的最先进方法进行定性比较。

训练期间使用和不使用 Lte 的定制结果。注意权重在交叉注意图的左下角标注。

不同模型变体的定性消融研究。

该方法可以应用于各种下游任务。从上到下:本地化定制、 表达修改和组合生成。

PersonaMagic 可以适应非面部领域,展示了其超越面部内容的通用性。

将PersonaMagic集成到预训练的个性化模型中,可以改善结果中的面部细节。
结论
文中介绍的PersonaMagic是一种高保真人脸定制技术,它利用基于综合分析的阶段调节文本调节策略。引入了一个轻量级网络,通过动态词嵌入来实现这种调节机制,有效地捕获身份信息,同时避免过度拟合。此外,文中提出了一个串联平衡损失来解决文本对齐和身份保存之间的权衡。大量实验证明了该方法与最先进的方法相比具有卓越的性能,在保真度和可编辑性方面都表现出色,并展示了其在各种下游定制任务中的有效性。