编辑 | 绿罗
了解湍流平流粒子的统计和几何特性是一个具有挑战性的问题,对于许多应用的建模、预测和控制至关重要。例如燃烧、工业混合、污染物扩散、量子流体、原行星盘吸积和云形成等。
尽管过去 30 年在理论、数值和实验方面做出了很多努力,但现有模型还不能很好地再现湍流中粒子轨迹所表现出的统计和拓扑特性。
近日,意大利罗马第二大学(University of Rome Tor Vergata)的研究人员,提出了一种基于最先进的扩散模型的机器学习方法,可以在高雷诺数的三维湍流中生成单粒子轨迹,从而绕过直接数值模拟或实验来获得可靠的拉格朗日数据的需要。
令人惊讶的是,该模型对极端事件表现出很强的通用性,产生了更高强度和稀有性的事件,但仍然符合实际统计数据。这为生成用于预训练拉格朗日湍流的各种下游应用的合成高质量数据集铺平了道路。
相关研究以《Synthetic Lagrangian turbulence by generative diffusion models》为题,于 2024 年 4 月 17 日发布在《Nature Machine Intelligence》上。

论文链接:https://www.nature.com/articles/s42256-024-00810-0
研究背景
拉格朗日湍流是与工程、生物流体、大气、海洋和天体物理学中的分散和混合物理学相关的许多应用和基本问题的核心。
在过去的 30 年里,科学家提出了许多不同的拉格朗日现象学模型。然而,尽管所有这些先前的尝试都能够很好地重现湍流统计的一些重要特征,但仍然缺乏一种系统的方法来生成具有正确的多尺度统计的合成轨迹。
因此,需要新的方法来解决这个问题。机器学习方法在解决流体力学中的开放性问题方面显示出强大的潜力。
考虑到现有技术,还缺乏基于方程和数据驱动的工具来生成 3D 单粒子或多粒子拉格朗日轨迹,这些轨迹具有与实验和直接数值模拟 (DNS) 定量一致的统计和几何特性。
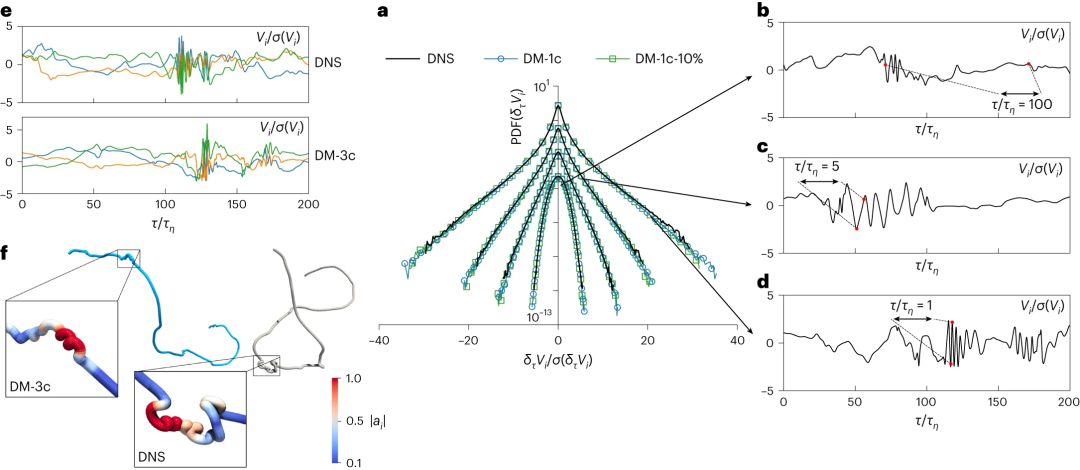
图示:DNS 和 DM 的比较。(来源:论文)
在各种湍流应用中,对合成生成高质量和高数量数据的需求至关重要,特别是在拉格朗日域中,即使只有一条轨迹也需要在巨大的空间域上再现整个欧拉场,这对于 DNS 来说通常是一项艰巨或不可能的任务,对于实验来说也是极其费力的。
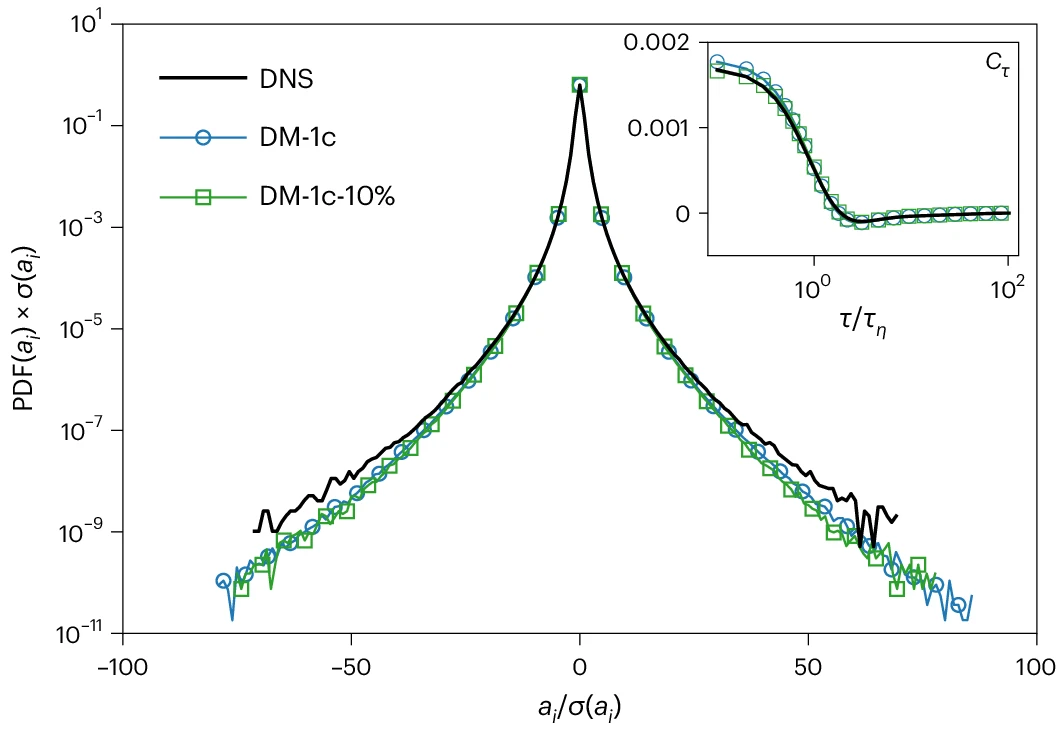
图示:加速度统计。(来源:论文)
基于扩散模型的机器学习方法
在此,研究人员提出了一种随机数据驱动模型,能够匹配高雷诺数下均匀和各向同性湍流中单粒子统计的数值和实验数据。
该模型基于最先进的生成式扩散模型(DM)。研究训练了两个不同的 DM:DM-1c,它生成拉格朗日速度的单个分量;DM-3c,它同时输出所有三个相关分量。
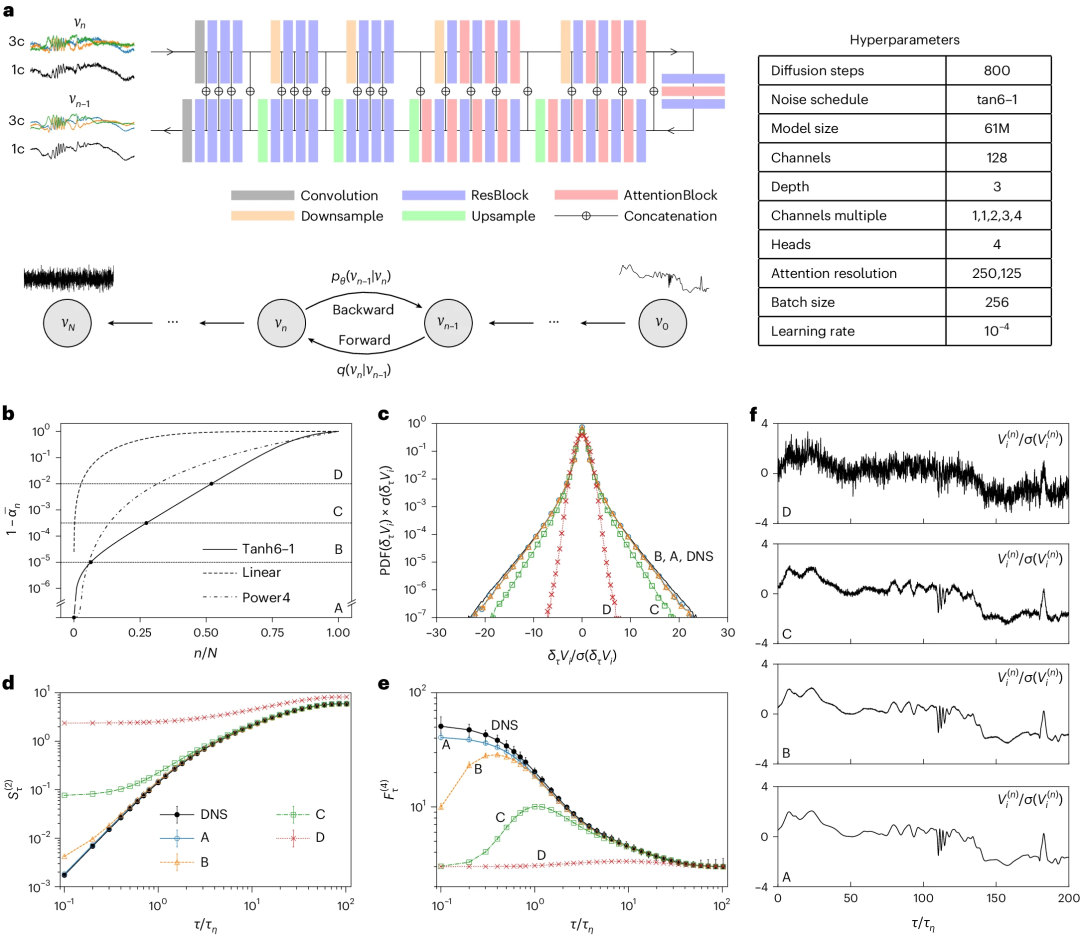
图示:DM 说明及其后向生成过程的深入研究。(来源:论文)
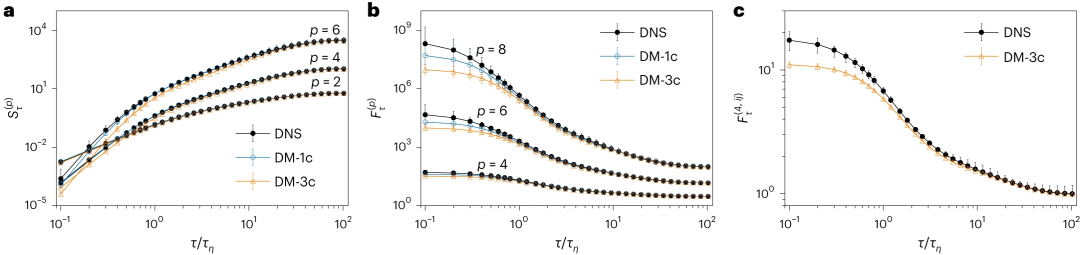
所提合成生成协议(protocol)能够在整个可用频率范围内重现速度增量的缩放,并在原始训练数据中为所有统计收敛矩达到八阶。此外,该协议成功捕获了高达 60 个标准差甚至更高的加速度波动,包括三个速度分量之间的互相关性。
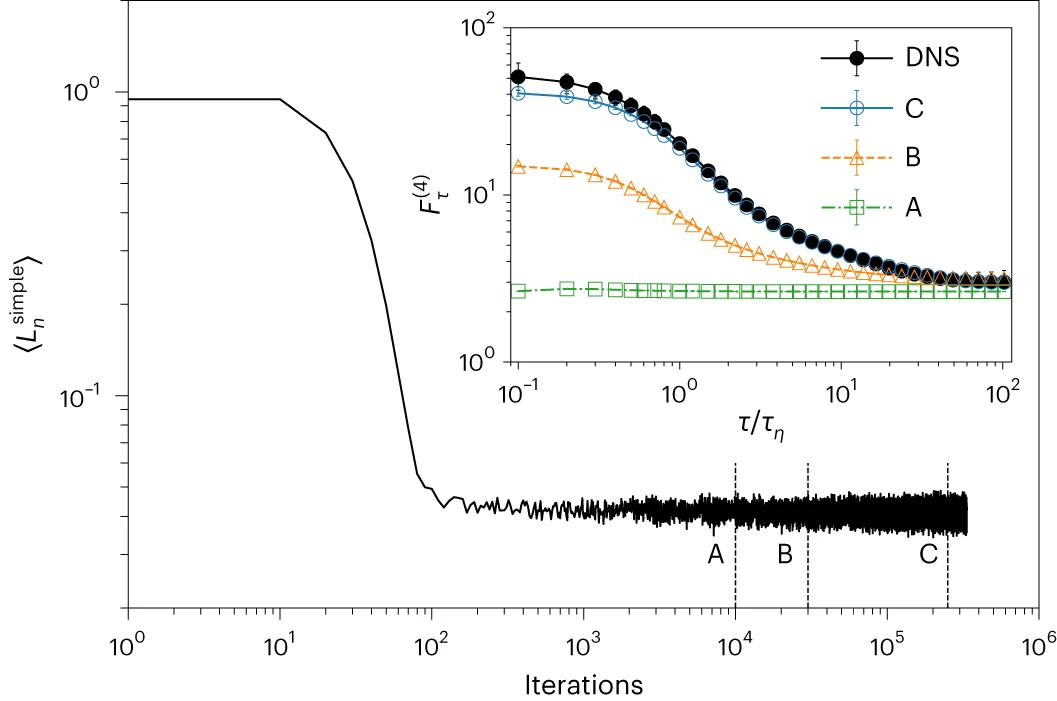
图示:DM 训练协议。(来源:论文)
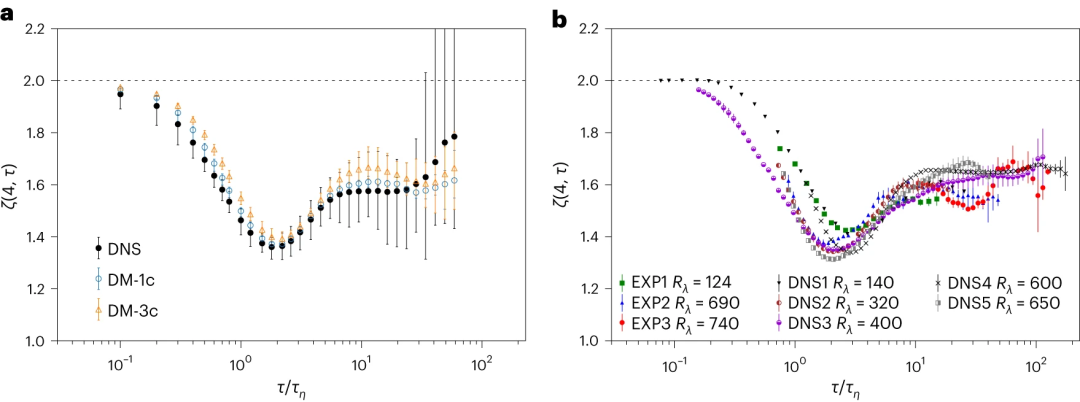
研究人员使用从 Rλ ≃ 310 处的 DNS 获得的高质量数据来训练模型。结果还显示出与四阶、六阶和八阶广义平坦度的数值实值数据非常吻合,由于间歇性波动的存在,其强度比高斯统计量存在时的期望值大一个数量级。
值得注意的是,模型表现出很强的泛化特性,能够合成训练阶段从未遇到过的强度的事件。这些极端波动是由小规模涡陷和急转弯轨迹造成的,具有前所未有的偏移和稀有性,始终遵循训练数据中固有的现实统计数据。
图示:速度增量的多尺度统计特性。(来源:论文)
图示:逐个尺度的间歇性特性。(来源:论文)
模型展示了跨时间尺度重现大多数统计基准的能力,包括速度增量的肥尾分布、反常幂律和耗散尺度周围增加的间歇性。在耗散标度以下观察到轻微偏差,特别是在加速度和平坦度统计数据中。
泛化性和可解释性
DM 显示出生成具有极其强烈事件的轨迹的能力,从而泛化超出训练阶段吸收的信息,同时仍然保留现实的统计特性。与从较小的训练数据集测量的结果相比,从 DM 生成的较大数据集测量的概率密度函数(PDF)的扩展尾的惊人观察清楚地说明了这一点。
DM 学习的用于生成正确的多次波动集的基本物理模型仍然难以捉摸。DM 基于嵌套非线性高斯去噪,本质上类似于用于创建多重分形信号和测量的波动的多尺度累积。
综合随机生成模型具有显著的优势。它们(1)提供对开放数据的访问,而不会出现与实际数据使用相关的版权或道德问题;(2)能够生成高质量和高数量的数据集,这些数据集可用于训练需要此类数据作为输入的其他模型。
最终目标是提供合成数据集,使下游应用程序的新模型能够达到更高的准确性,用合成预训练取代真实数据预训练的必要性。
注:封面来自网络


