近日,微软研究院联合华盛顿大学、斯坦福大学、南加州大学、加利福尼亚大学戴维斯分校以及加利福尼亚大学旧金山分校的研究人员共同推出了 LLaVA-Rad,这是一种新型的小型多模态模型(SMM),旨在提升临床放射学报告的生成效率。该模型的推出不仅标志着医学图像处理技术的一大进步,也为放射学的临床应用带来了更多的可能性。
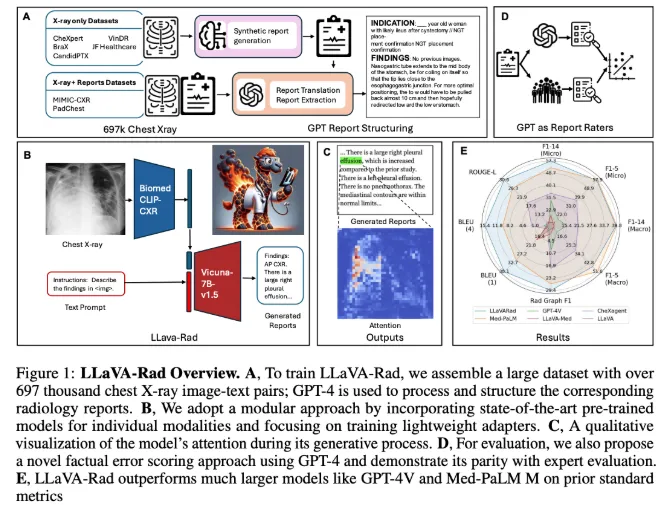
在生物医学领域,基于大规模基础模型的研究已经展现出良好的应用前景,尤其是在多模态生成 AI 的发展下,可以同时处理文本与图像,从而支持视觉问答和放射学报告生成等任务。然而,目前仍然存在诸多挑战,例如大模型的资源需求过高,难以在临床环境中广泛部署。小型多模态模型虽然在效率上有所提高,但与大型模型相比,性能仍存在显著差距。此外,缺乏开放源代码模型以及可靠的事实准确性评估方法也使得临床应用受到限制。
LLaVA-Rad 模型的训练基于来自七个不同来源的697,435对放射学图像与报告的数据集,专注于胸部 X 光(CXR)成像,这是最常见的医学影像检查类型。该模型的设计采用了一种模块化的训练方式,包括单模态预训练、对齐和微调三个阶段,利用高效的适配器机制将非文本模态嵌入文本嵌入空间。尽管 LLaVA-Rad 的规模小于一些大型模型,如 Med-PaLM M,但在性能上却表现优异,尤其是在 ROUGE-L 和 F1-RadGraph 等关键指标上,相较于其他同类模型提升了12.1% 和10.1%。
值得一提的是,LLaVA-Rad 在多个数据集上均保持了优越的性能,即便是在未见过的数据测试中也表现稳定。这一切都归功于其模块化设计和高效的数据利用架构。此外,研究团队还推出了 CheXprompt,一个用于自动评分事实正确性的指标,进一步解决了临床应用中的评估难题。
LLaVA-Rad 的发布,无疑是推动基础模型在临床环境中应用的一大步,为放射学报告生成提供了一种轻量级且高效的解决方案,标志着技术与临床需求之间的进一步融合。
项目地址:https://github.com/microsoft/LLaVA-Med
划重点:
🌟 LLaVA-Rad 是微软研究团队推出的小型多模态模型,专注于放射学报告的生成。
💻 该模型经过697,435对胸部 X 光图像与报告的训练,实现了高效且优越的性能。
🔍 CheXprompt 是配套推出的自动评分指标,帮助解决临床应用中的评估难题。


