之前老喜欢死记硬背transformer的网络架构,虽然内容并不复杂,但是发现这个transformer模块中的positional encoding在死记硬背的情况之下很容易被忽略。为了更好地理解为什么transformer一定需要有一个positional encoding,简单推了一下公式
先说结论:没有Positional Encoding的transformer架构具有置换等变性。
证明如下:
1. 对self-attn的公式推导

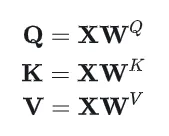
其中的是可训练的权重矩阵。首先计算Query和Key之间的点积,得到注意力权重矩阵:
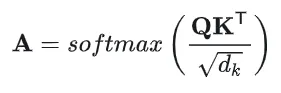
然后计算自注意力输出:
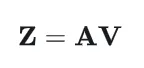
2. 假设对输入进行置换

置换后的Query, Key, Value的公式分别为:
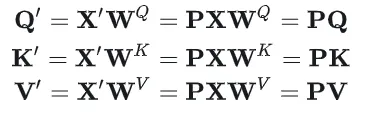
注意力矩阵的计算则变化为:

由于P是置换矩阵,满足=,且P=I,所以:
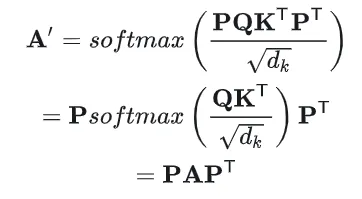
所以最终的输出可以这样写:
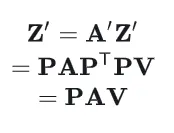
这样就可以证明,transformer架构在没有Positional Encoding计算的情况下具有置换等变性,换句话说,输入序列中元素的排列方式不会影响模型对它们的处理方式,只是输出的顺序相应地改变。
3. 添加Positional Encoding之后的影响
加入Positional Encoding之后,置换后的输入为:
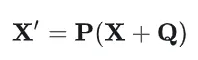
由于P是固定的,加入Positional Encoding之后,输入序列的置换将导致模型的输出发生变化,模型能够区分不用的序列:
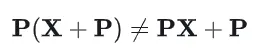
从公式上看,在没有位置编码的情况下,自注意力机制的计算只涉及输入向量的内容,不涉及任何位置信息,且对输入序列的置换是等变的。
加入位置编码后,输入向量包含了位置信息,打破了自注意力机制的置换等变性,使模型能够对序列中的元素位置敏感。