 SFT的text2sql方法
SFT的text2sql方法
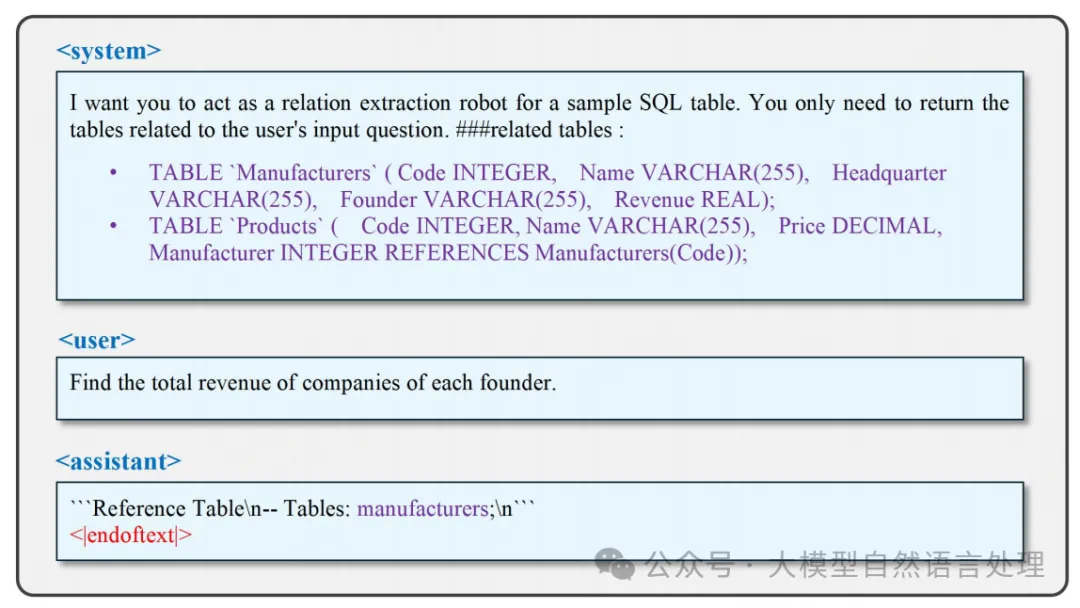
SFT使模型能够遵循输入指令并根据预定义模板进行思考和响应。如上图是用于通知模型在推理过程中响应角色的角色标签。后面的内容表示模型需要遵循的指令,而后面的内容传达了当前用户对模型的需求。后面的内容代表模型的预期输出,也可以定义为模型预测的标签。在监督微调期间,模型根据和中的内容预测后面的内容,然后将其与标签进行比较以计算损失函数。标记作为结束标记,以防止模型在后续推理阶段偏离思路,从而减少推理时间。通过定义监督微调模板,模型可以在推理时根据模板唤起微调知识,用户可以从预先建立的响应模板中提取答案。
text2sql一些研究涵盖两个基本任务:schema_linking和SQL生成。
- Schema Linking: 主要目的是识别和提取与问题相关的表,并通过分步推理和链式思维方法在有限内存下处理大规模数据库。
- SQL 生成: 主要目的是根据模式链接任务的结果生成准确的SQL查询语句,同时通过减少输入表的数量来降低内存消耗。
方法
 LR-SQL方法框架
LR-SQL方法框架
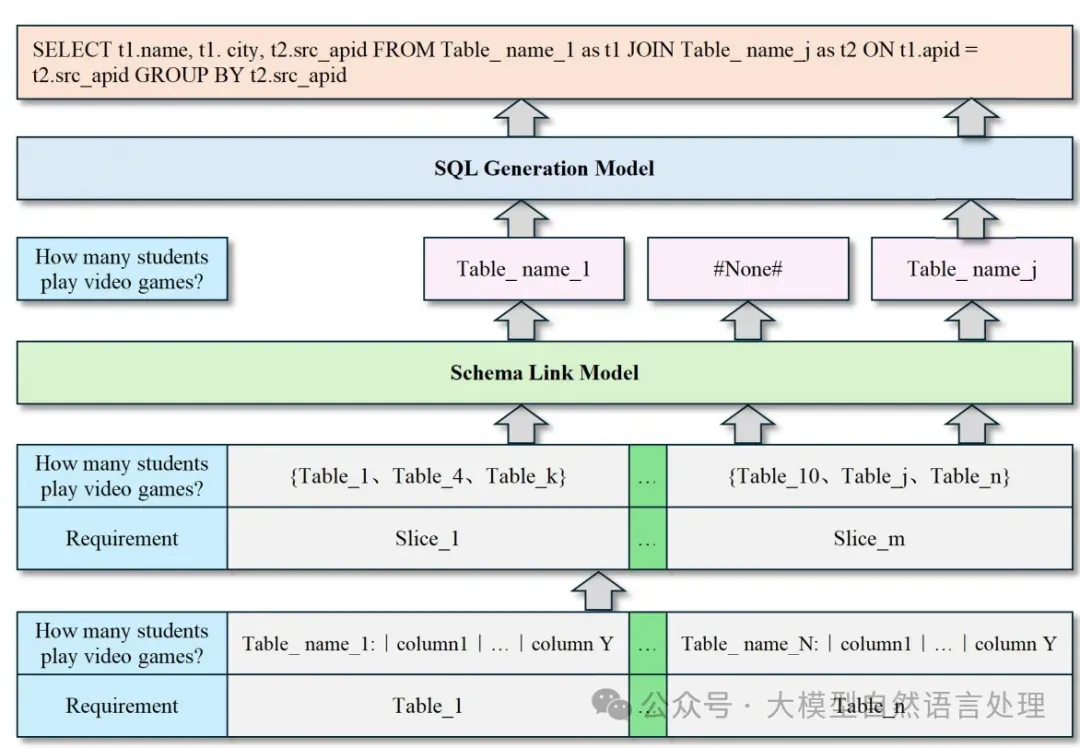
提出了LR-SQL方法,解决低资源场景下的Text2SQL任务,具体如下:
1.schema_link模型:首先,LR-SQL方法包含两个监督微调模型:schema_link模型和SQL生成模型。schema_link模型的主要作用是简化整个流程,通过将完整的数据库分解为灵活的表组合,使模型能够从这些分散的切片中学习数据库内关系。
2.数据分解:在schema_link模型的微调过程中,LR-SQL将数据库分解为多个切片,每个切片具有可调节的表数量。这种方法允许模型根据GPU内存限制灵活地覆盖不同数量的表。
 LR-SQL的监督模板构建
LR-SQL的监督模板构建
 图片
图片

将数据库中的表分解成多个片段,每个片段包含一定数量的表和其列的描述。
3.思维链:为了增强模型在推理过程中感知各个离散切片之间关系的能力,LR-SQL训练了模型的链式思维能力。COT能力使模型能够逐步引导自己生成最终结果。
 LR-SQL训练
LR-SQL训练
4.SQL生成模型:在schema_link模型微调完成后,预测的目标表和问题被发送到SQL生成模型以生成最终的SQL查询。该模型仅使用包含目标表的少量表进行微调,从而显著减少了所需的内存。
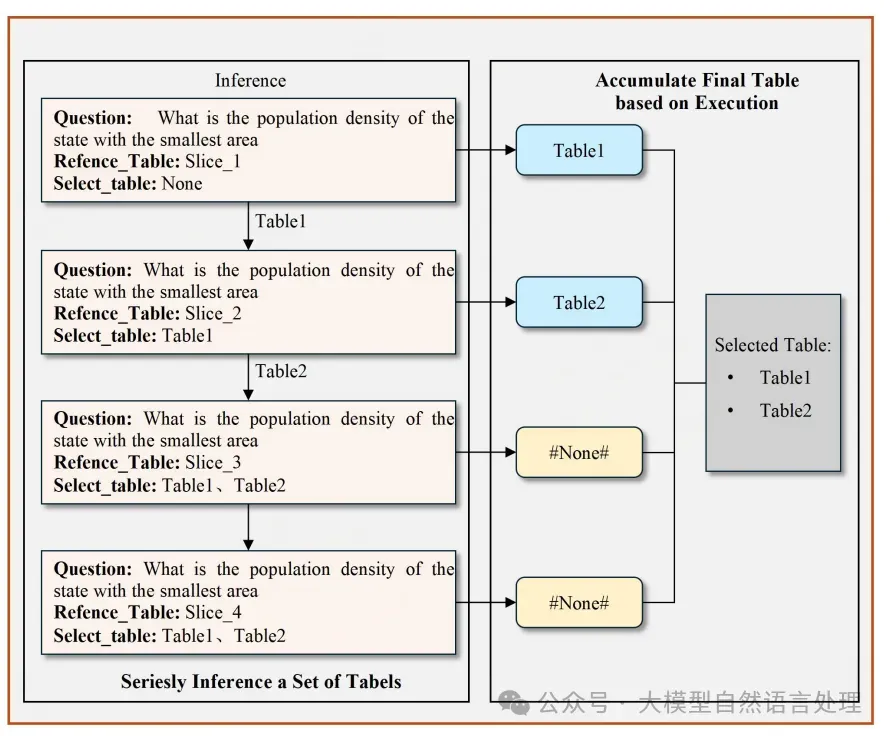 在推理阶段,与训练相比,模型处理长文本所需的内存需求大幅减少。
在推理阶段,与训练相比,模型处理长文本所需的内存需求大幅减少。
实验
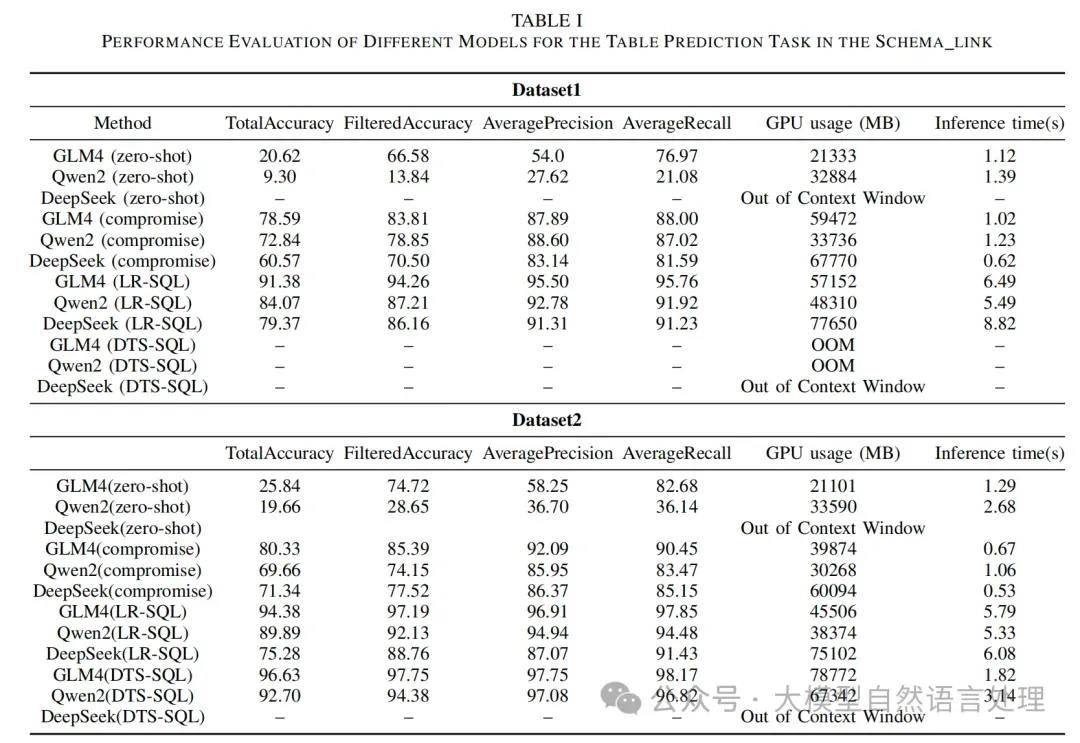 schema_link模型评估:LR-SQL方法在两个数据集上的总准确率分别为91.38和94.38,过滤准确率分别为94.26和97.19,平均精度分别为95.50和96.91,平均召回率分别为95.76和97.85。与现有方法相比,LR-SQL在保持较高准确率的同时,显著减少了GPU内存使用。
schema_link模型评估:LR-SQL方法在两个数据集上的总准确率分别为91.38和94.38,过滤准确率分别为94.26和97.19,平均精度分别为95.50和96.91,平均召回率分别为95.76和97.85。与现有方法相比,LR-SQL在保持较高准确率的同时,显著减少了GPU内存使用。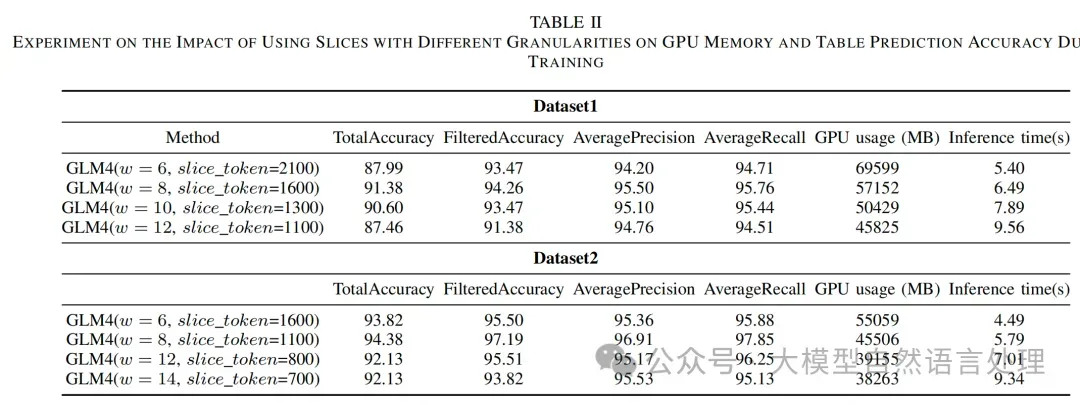 切片大小对性能的影响:实验还探讨了不同切片大小对模型性能和GPU内存使用的影响。结果表明,当切片大小适中时,模型的性能最佳。
切片大小对性能的影响:实验还探讨了不同切片大小对模型性能和GPU内存使用的影响。结果表明,当切片大小适中时,模型的性能最佳。
参考文献
- LR-SQL: A Supervised Fine-Tuning Method for Text2SQL Tasks under Low-Resource Scenarios,https://arxiv.org/pdf/2410.11457


