不仅有主持人,还能得到不同AI专家的解答。
今年 4 月,斯坦福大学推出了一款利用大语言模型(LLM)辅助编写类维基百科文章的神器。它就是开源的 STORM,可以在三分钟左右将你输入的主题转换为长篇文章或者研究论文,并能够以 PDF 格式直接下载。
具体来讲,STORM 在 LLM 的协助下,通过检索、多角度提问和模拟专家对话等方式,在整理收集到的信息基础上生成写作大纲,并最终形成一份详细、深入和准确的内容报告。STORM 尤其擅长需要大量研究和引用的写作任务。更难得的是,用户可以直接在 STORM 的网站免费体验。
此后,STORM 不断推出新的功能和服务,在 GitHub 上的 Star 量已经超过了 12k。
GitHub 地址:https://github.com/stanford-oval/storm
就在最近,该团队又推出全新功能 ——Co-STORM。与 STORM 的区别在于,它引入了协作对话机制,并采用轮次管理策略,实现流畅的协作式 AI 学术研究。功能包括如下:
Co-STORM LLM 专家:这种类型的智能体会根据外部知识来源生成答案并能根据对话历史提出后续问题。
主持人(Moderator):该智能体会根据检索器发现但未在前几轮直接使用的信息生成发人深省的问题。当然,问题生成也可以基于事实。
人类用户:人类用户将主动观察对话以更深入地了解主题,或者通过注入对话来引导讨论焦点,积极参与对话。
Co-STORM 的界面是下面这样的。
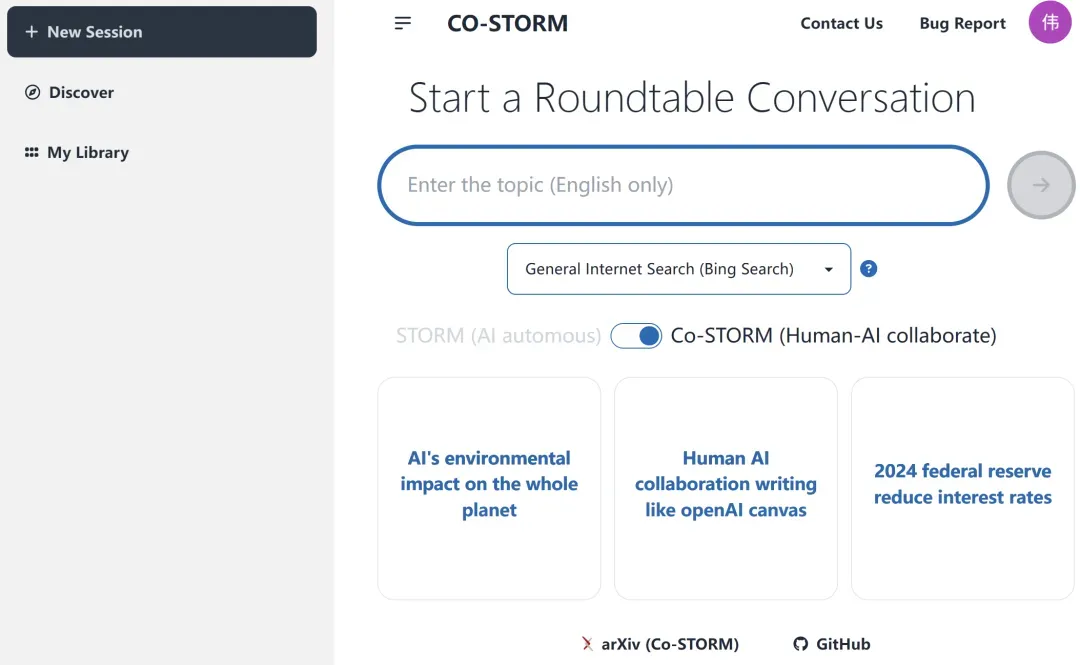
体验地址:https://storm.genie.stanford.edu/
我们让 Co-STORM 就战争与和平(war and peace)主题来生成一篇文章,大约需要三分钟。
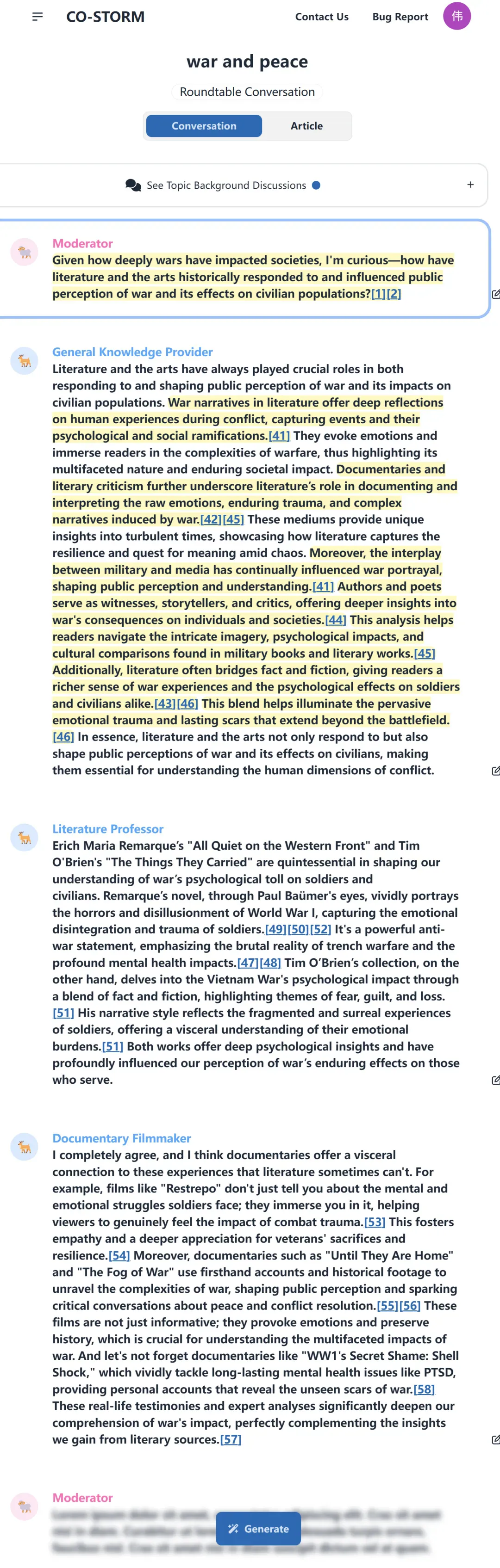
在生成文章之后,我们可以看到,主持人提出问题,并得到基本信息提供者、文学教授、纪录片导演等不同 AI 智能体的回复,然后开启新一轮次的提问。
此外,Co-STORM 的相关论文已被 EMNLP 2024 主会议收录。

论文地址:https://www.arxiv.org/pdf/2408.15232
运行原理概览
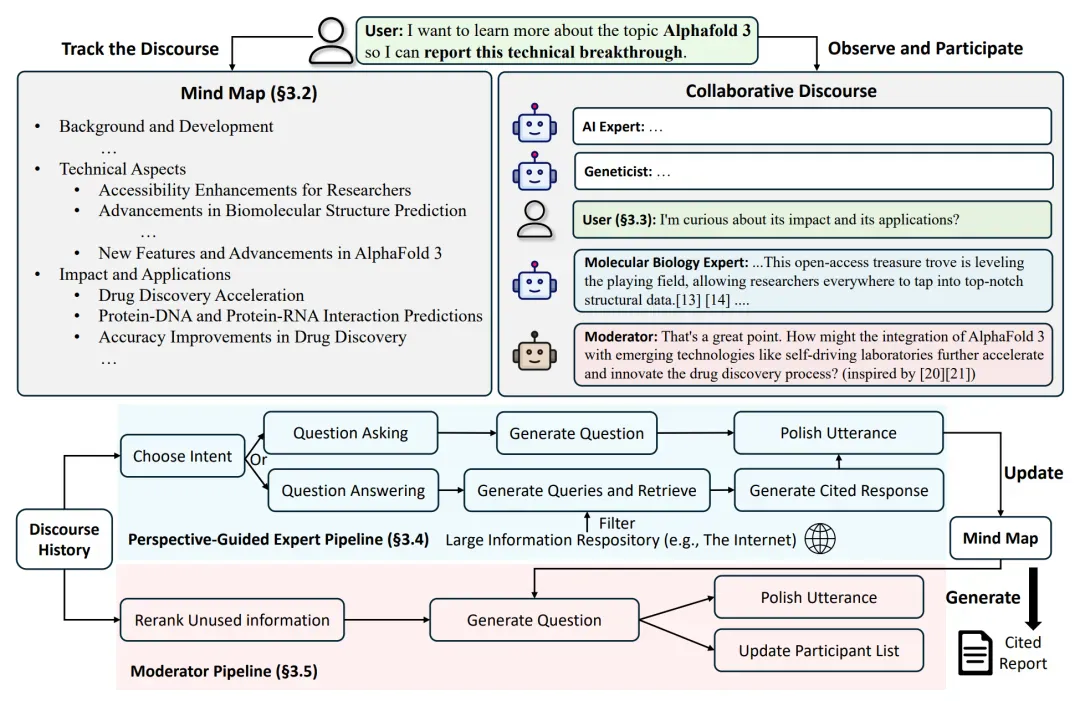
下图为 Co-STORM 框架。整体而言,Co-STORM 模拟用户、观点引导专家和主持人之间的协作对话。
运行原理如下所示:首先维护动态更新的思维导图(3.2),从而帮助用户跟踪和参与对话(3.3)。
在 3.4,提示模拟专家根据对话历史来确定对话意图,并生成基于互联网的问题或答案。
在 3.5,提示模拟主持人利用未使用的信息和思维导图生成新问题,从而自动引导对话。
最后,思维导图可用来生成完整的引用报告以作为总结。
评估结果
自动评估可以实现可扩展测试,并允许对用户行为进行一致的模拟。
研究者将 Co-STORM 与以下基线进行比较:(1)RAG Chatbot,该基线从搜索引擎检索信息并通过一问一答范式与用户交互;(2)STORM + QA,该基线使用 STORM 框架为给定主题生成报告以提供基本信息。
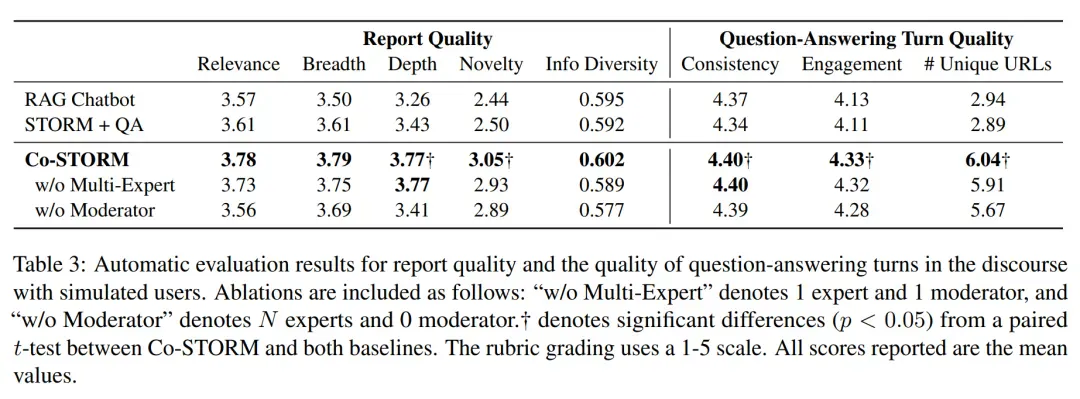
下表 3 展示了报告质量和对话中问答轮次质量的评估结果。问答轮次和最终报告是人类与 Co-STORM 交互时学习的主要来源。STORM + QA 在研究给定主题时考虑了多种观点,与 RAG Chatbot 相比,确实提高了报告质量所有四个评分维度的表现。
同样,Co-STORM 的表现优于 RAG Chatbot,特别是在深度和新颖性方面,它通过模拟具有多个智能体角色的协作对话,类似于圆桌讨论。就对话质量而言,Co-STORM 中的问答轮次在一致性和参与度方面明显优于两个基线。
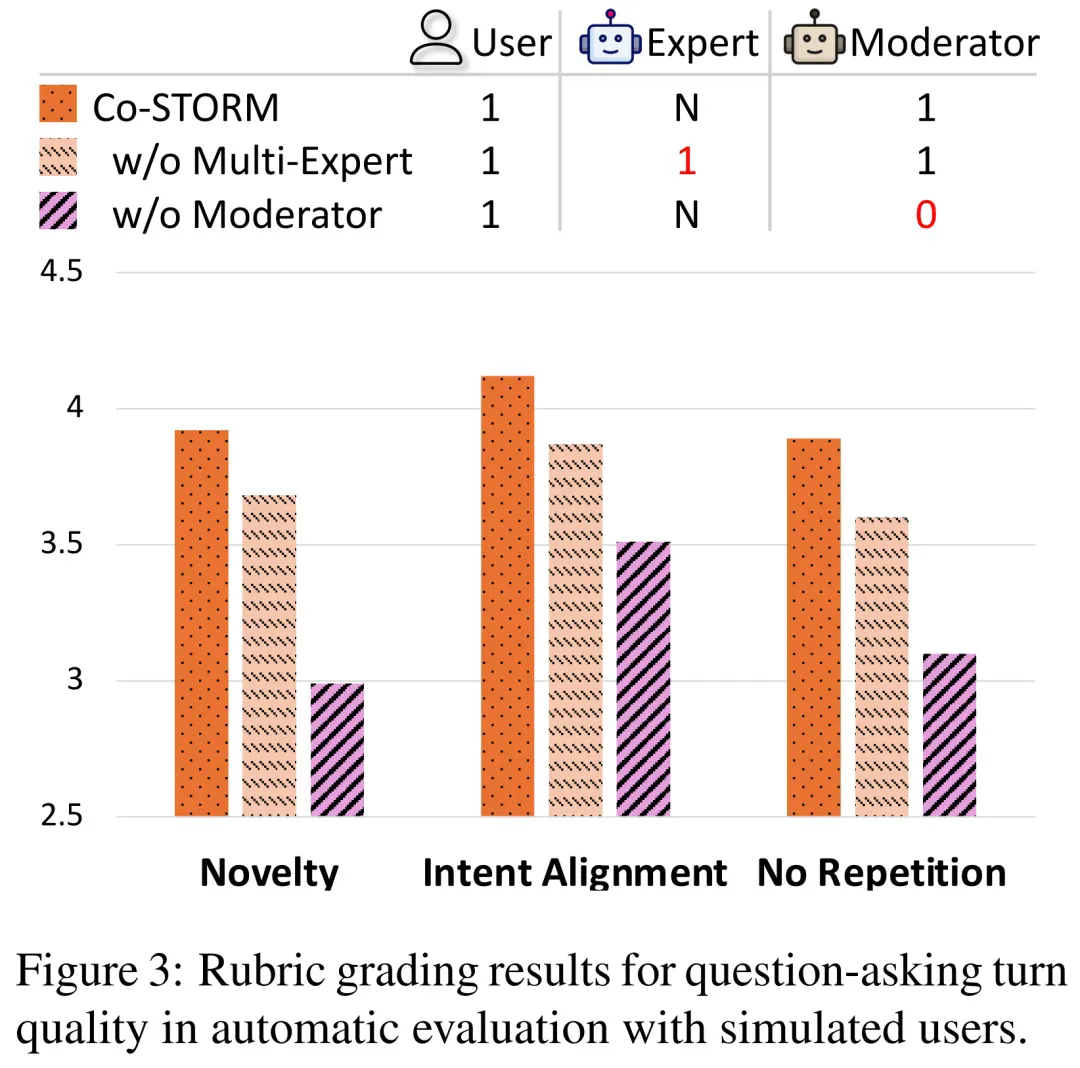
Co-STORM 的一个关键特性是 LM 智能体可以代表用户提问。如下图 3 所示,在检查提问轮次时,Co-STORM 多智能体设计的优势变得更加明显,只需要一位专家和一位主持人就可以极大地获益。
重要的是,CoSTORM 中的主持人角色会根据有关主题的未使用信息提出问题。这样的角色代表拥有更多已知未知(known unknowns)的人,有效地引导对话,帮助用户在未知未知(unknown unknowns)空间中发现更多信息。
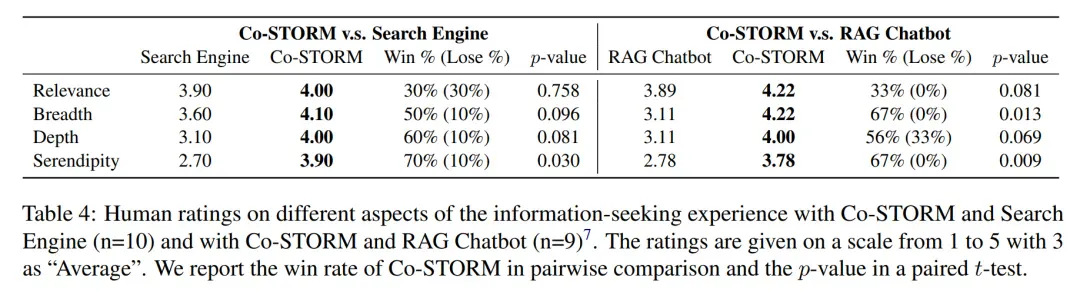
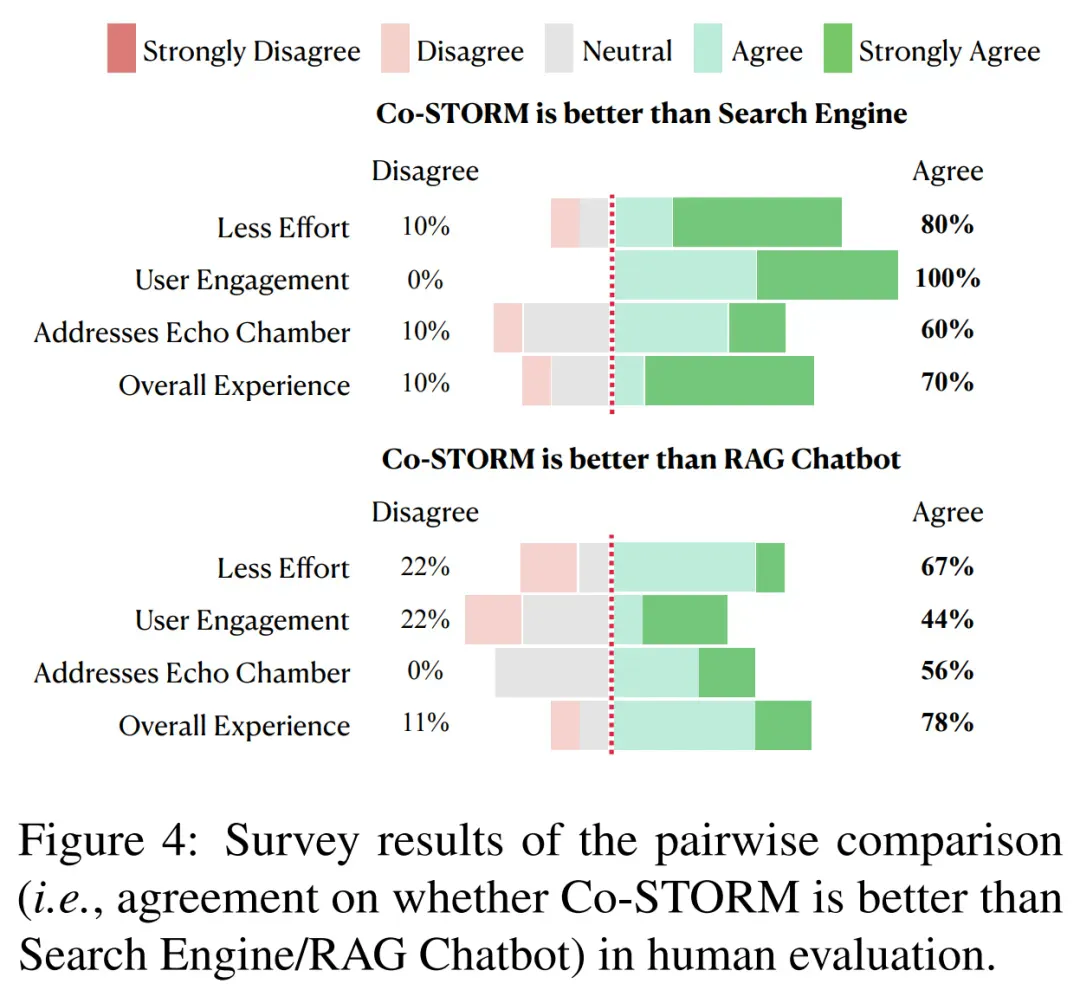
下表 4 为人工评分结果,图 4 为成对比较结果。可以得出结论,CoSTORM 可以帮助用户找到与其目标相关的更广泛、更深层次的信息。
更多技术细节和评估结果请参考原论文。


