编辑/绿萝
由于深度学习的发展进步,从视频中提取可解释的物理定律引发了计算机视觉社区的兴趣,但仍然面临巨大的挑战。
控制方程(例如 PDE、ODE)的发现可能促进我们对复杂动力系统行为的理解、建模和预测。收集数据的日益丰富和机器学习的进步带来了动态系统建模的新视角。
近日,来自中国人民大学和中国科学院大学、美国东北大学的研究团队提出了一个端到端的无监督深度学习框架,根据录制的视频揭示运动物体呈现的显式动力学控制方程。
模拟动态场景的实验表明,所提出的方法能够提取封闭形式的控制方程并同时识别视频记录的多个动力系统的未知激励输入,这填补了文献中没有现有方法可用且适用于解决此类问题的空白。
该研究以「Distilling Governing Laws and Source Input for Dynamical Systems from Videos」为题,发布在预印平台 arXiv 上。
控制方程的发现可能促进我们对复杂动力系统行为的理解、建模和预测。
对数据驱动的控制方程发现的研究,仍然主要集中在从给定的物理状态测量中建立数学模型。随着深度学习的进步,人们对从视频中发现物理规律的兴趣扩大了。
为了提高已发现物理定律的可解释性,学习显式动力学(例如,封闭形式的控制方程或其参数)最近在物理场景理解中变得越来越流行。然而,这些方法需要对物理定律或控制方程的结构有很强的先验知识。此外,对于那些方法,物理是在像素坐标中建模的,这限制了复杂动态系统(例如,ODE)的发现,其中物理状态需要在另一个物理坐标系中描述。
因此,直接从原始视频中发现控制方程仍然是一个巨大的挑战,尤其是在源输入未知的情况下。
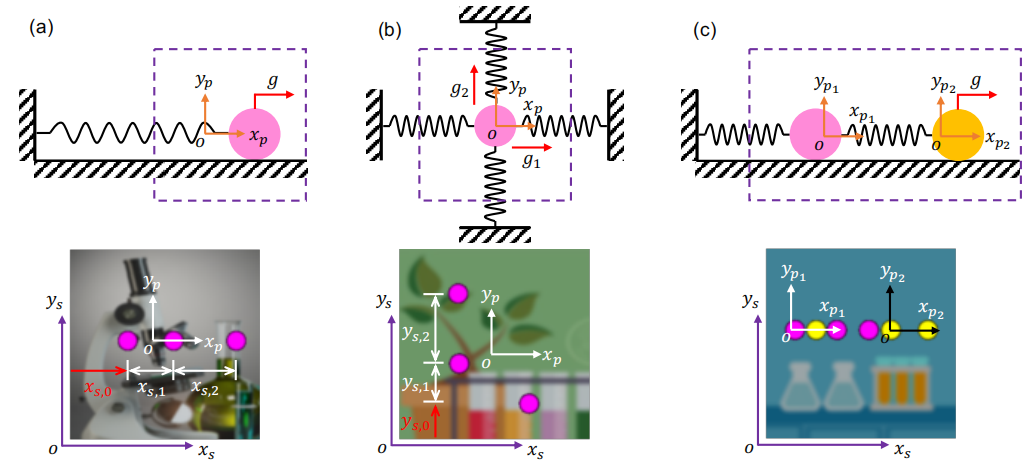
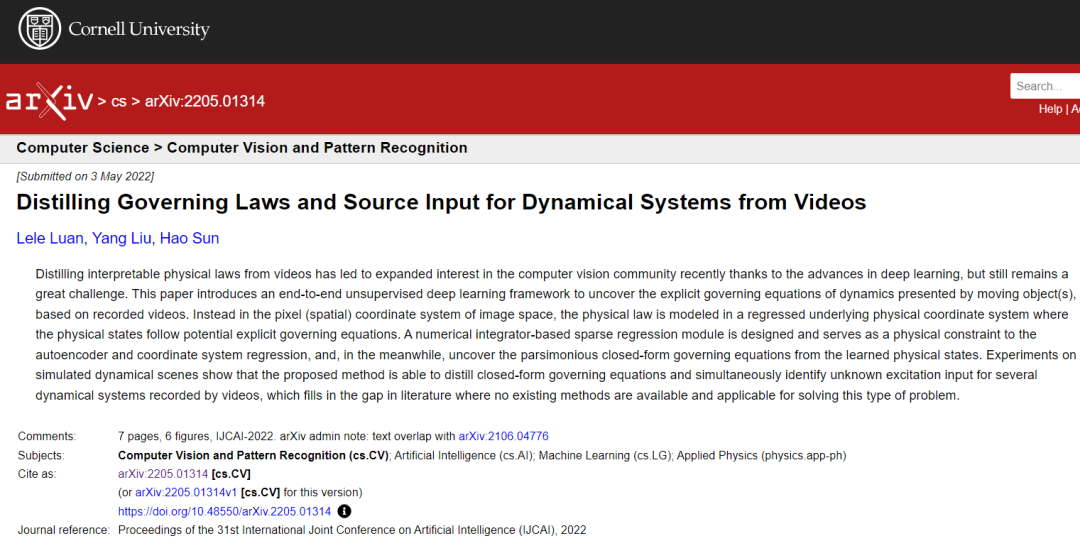
图 1:研究的由未知输入激发的动力系统。
在这项工作中,研究人员提出了一个端到端的无监督深度学习框架,以从视频中揭示受未知输入影响的动力系统的闭式控制方程。要解决的任务,如图 1 所示,展示了所构建的范式,旨在同时提取运动物体的物理状态,揭示其受控的封闭式方程,并识别系统输入。
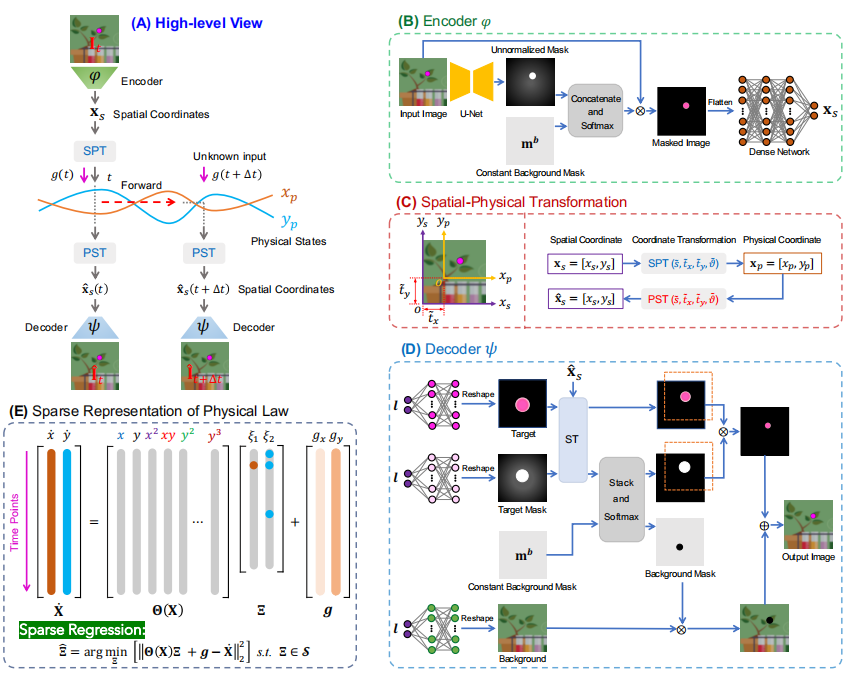
图 2:所提出的端到端无监督深度学习的架构示意图,以同时揭示封闭形式的控制方程并从视频中识别动力系统的输入(单个运动物体情况)。
与现有的深度学习方法通常从运动物体的空间/像素坐标轨迹中发现物理规律不同,研究人员所提方法从回归物理坐标系中的物理状态揭示了显式控制方程,这使得发现更复杂的动力系统成为可能。此外,物理状态的提取不是独立于编码器-解码器和物理坐标系回归,而是在底层物理定律的约束下进行的。联合优化不仅有助于物理状态的提取,而且导致了封闭形式的控制方程和未知输入的识别。
所研究动力系统的发现结果如图 3 所示,其中揭示了物理轨迹、它们的控制方程和外部激励。这表明控制方程,尤其是它们的系数与基本事实完全相同。而缩放后 TMTD 系统,还表明且该方法能够处理出现多个运动物体的情况在场景中。
图 3:所研究动力系统的发现结果。
接下来,研究人员通过从有噪声的视频中发现控制方程来进一步测试所提方法对噪声的稳健性。如图 4 所示。结果表明,由于噪声的影响,与从没有噪声的视频中发现相比,识别出的系统输入噪声更大,但控制方程和物理轨迹仍然未被发现和正确提取。
目前,直接从视频中发现具有未知输入的动态系统的控制方程方面的文献仍然很少。研究人员将图 2 中所示的坐标一致编码器解码器替换为传统的卷积编码器-解码器,并将得到的方法作为另一个基线。发现该网络能够从视频中提取物理定律。由于提取的潜在变量不能正确地表示基于位置的物理状态,该方法未能揭示潜在的物理规律。此外,传统的自动编码器无法保证运动物体的物理状态和真实位置之间的固定关系。
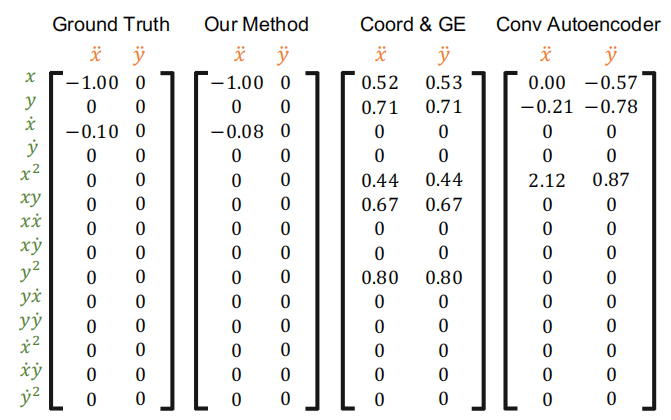
图 4:基线的发现结果。
研究人员提出了一种端到端的无监督深度学习方案,从记录运动物体的原始视频中揭示出明确的可解释物理定律,这些运动物体代表了由未知输入激发的动力系统。
该工作是首次尝试从具有未知输入激励的动态系统的原始视频中发现可解释的物理定律。但方法也存在一些局限性,例如,它不能处理非静止背景、带扭曲的视频和 3D 空间中的移动对象。研究人员将在正在进行和未来的研究中解决这些挑战。
论文链接:https://arxiv.org/abs/2205.01314


