编辑丨&
自1971年第一个商用微处理器的草图面世以来,芯片设计已经取得了长足的进步。但是,随着芯片变得越来越复杂,设计人员必须解决的问题也越来越复杂。而我们目前的工具并不总是能胜任这项任务。
当今使用的自动化工具通常无法解决设计过程中的现实问题,这意味着必须人工介入,这使得该过程比芯片制造商希望的更费力和耗时。
毫不奇怪的是,人们更倾向于采用 AI 来加速芯片设计,正如英特尔所做的那样。但AI 本身不足以满足多个约束同时处理的需要。
事实上,来自英特尔 AI 实验室的团队最近尝试开发一种基于 AI 的解决方案来处理一项称为布局规划的棘手设计任务,但在此之中他们找到了一个基于非 AI 方法的更成功的工具。
他们的研究成果以「AI ALONE ISN’T READY FOR CHIP DESIGN」为题,于 2024 年 11 月 21 日刊登于《IEEE Spectrum》。

团队相信,该领域不应该太快就否定传统技术。结合两种方法优点的混合方法,虽然目前是一个未被充分探索的研究领域,但将被证明是最富有成效的前进道路。
AI 算法的危险
在架构得到解决并且逻辑和电路已经解决之后,芯片设计中最大的瓶颈之一发生在物理设计阶段。一个系统级芯片 (SoC) 平均有大约 100 个高级模块,由数百到数千个宏和数千到数十万个标准单元组成。
而在后续的布局规划中,功能块的排列需要满足某些设计目标,包括高性能、低功耗和成本效益。此类布局规划问题属于数学规划的一个分支,称为组合优化。如果读者曾经玩过俄罗斯方块,那么这就算已解决了一个非常简单的组合优化难题。
但在芯片设计中,需要求取问题的解决方案大得惊人。举例来说,在典型的 SoC 平面图中,大约有 10 的 250 次方个排列 120 个高级块的方法;相比之下,估计有 10 的 24 次方个宇宙中的星星的总量。
在面临这种量级,甚至在标准单元格的排列组合的数量要更甚几个量级的情况下,机器学习与大语言模型的设计影响就不大了。这样的编码任务与解决像布局规划这样的复杂优化问题相去甚远。
从理论上讲,可以通过训练变压器按顺序预测芯片上每个模块的物理坐标来创建一个基于 AI 的楼层规划器,类似于 AI 聊天机器人按顺序预测句子中的单词。但,对于人类,怎么使放置单元块时不重叠在一起很好理解,甚至学得很快,但这个概念对于计算机来说学习起来并不简单。
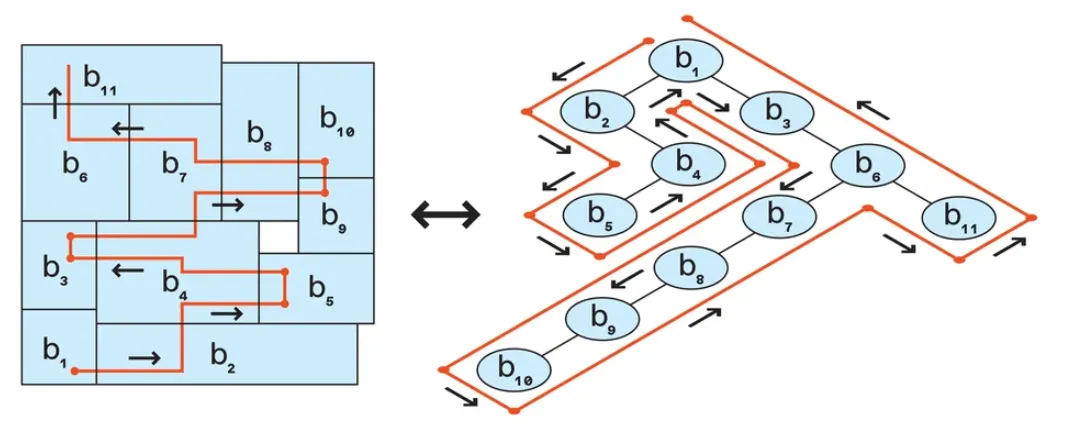
图 1:一个简单的平面图 [左] 可以用 B* 树数据结构 [右] 来表示。
团队采用了树状结构,随着树的生长,它会在向右和向上扇动时封装平面图。此外,因为块的位置是相对的而不是绝对的,所以这个结构还能保证无重叠的平面图。不需要预测放置的每个块的确切坐标。相反,可以根据块的维度以及其关系邻居的坐标和维度轻松计算。
但即便是在此基础上,AI 模型也产生了浪费时间寻求次优解决方案的问题。究其原因可能在于在于模型无法回溯。
回归传统的芯片设计思路
解决大量组合优化问题的一种常见方法是使用一种称为模拟退火 (SA) 的搜索技术。SA 可以逐步找到优化问题的最佳解决方案,而不必繁琐地检查每一种可能性。
如果生成的代价更低,那么方案可接受。如果情况稍坏一些,也可以接受。随着时间的推移,随着算法不断随机调整数据块,接受增加代价的操作的频率越来越低。
避免算法过早地陷入局部最优,需要给算法充足的发展余地,以此,可以获得最终的全局最优解。
虽然,当算法进行随机块更改以增加约束违规时,可以越来越多地进行拒绝这些操作,从而指示模型避免它们。但不幸的是,这种策略适得其反。
当增加 constraints 变量的权重以考虑这种刚性时,该算法在优化方面做得很差。模型没有努力修复导致全局最优值的分歧行为,而是反复导致模型无法逃避的局部最优值。
推进机器学习
为了解决上述问题,团队构思了 SA 的新变化,称之为约束感知 SA (CA-SA)。此变体使用两个算法模块。第一个是 SA 模块,它侧重于 SA 最擅长的方面:优化面积和线长。第二个模块选择随机约束冲突并将其修复。
使用这种方法,团队开发了一个开源的布局规划工具,可以同时运行 CA-SA 的多个迭代。他们称其为具有约束感知的并行模拟退火,或简称 Parsac。
为了了解 Parsac 在更真实的设计中的表现,团队在基准测试问题中添加了自己的约束,包括关于块放置和分组的规定。令人高兴的是,Parsac 在不到 15 分钟的时间内成功解决了拥有商业规模的高级布局规划问题,使其成为同类产品中已知最快的布局规划器。
除开正在开发的基于集合搜索的非 AI 技术以处理奇特的块布局规划问题,团队正在努力使 Parsac 适应宏放置。单独的 CA-SA 可能太慢,无法有效解决这种规模和复杂性的问题,而这正是机器学习可以提供帮助的地方。
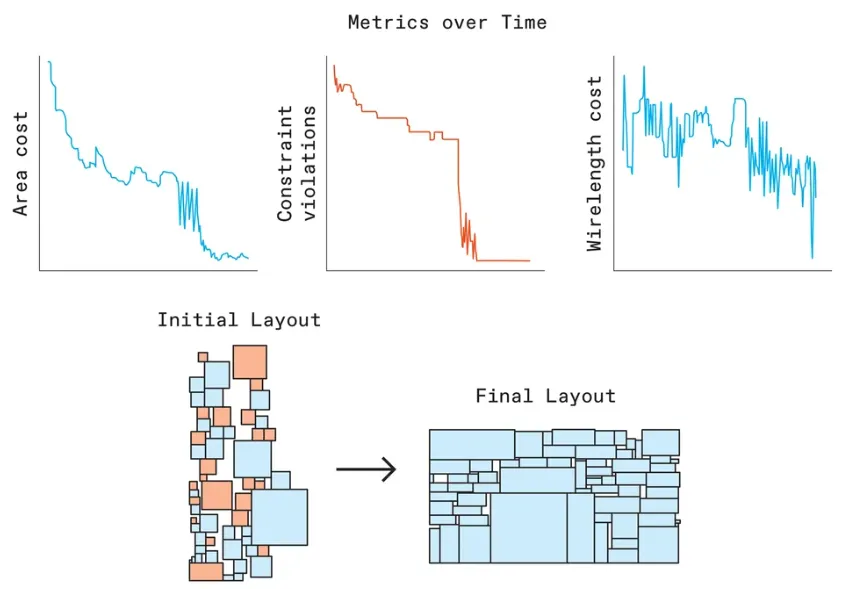
图 2:Parsac 的布局分析示意。
对于给定一个 SA 生成的平面图,可以训练一个 AI 模型来预测哪个操作会提高布局的质量。然后可以使用此模型来指导 CA-SA 算法的决策。该算法不会只采取随机或导向局部的操作,而是以一定的概率接受模型的“智能”操作。
通过与 AI 模型合作,Parsac 可以显著减少寻找最佳解决方案所需的操作数量,从而缩短其运行时间。在此基础上,允许一些随机操作仍然很重要,这可以避免算法再次陷入局部最优解,就像以往的失败案例一样。
此种或相近的方法可能有助于解决 floorplanning 之外的其他复杂组合优化问题。在芯片设计中,此类问题包括优化内核内互连的布线和布尔电路最小化,需要面临构建具有最少门和输入的电路来执行功能的挑战。
全新的裁定方式
随着研究人员寻求验证新的芯片设计工具,对现代基准测试的需求越来越迫切。最近基于旧基准或专有布局的研究对新型机器学习算法的性能提出了质疑。
该团队发布了两个数据集,现已在 GitHub 上提供。他们设计的布局充分体现了当代 SoC 平面图的广度和复杂性,范围从 20 到 120 个块不等,包括实际的设计约束。
尽管这些数据集是人工的,但团队还是很贴心的创建了平面图属性的详细统计分布,以贴合商用芯片的特征需求。有需求的人可以从这些发行版中采样,创建模拟真实芯片布局的综合布局图。
在研究末期,团队并不看好 AI 或者是基于 AI 的技术方案来解决棘手的优化问题。相反,他们预测混合算法将代替 AI 成为笑到最后的赢家。
通过学习识别最有前途的解决方案类型进行探索,AI 模型可以智能地指导 Parsac 等搜索代理,从而提高它们的效率,更快地解决问题,从而创建更复杂、更节能的芯片。
团队强调道,AI 可能无法完全自行创建芯片,甚至无法解决单个设计阶段。但是,当与其他创新方法相结合时,它将改变该领域的游戏规则。