具备原生中文理解能力,还兼容Stable Diffusion生态。
最新模型结构Bridge Diffusion Model来了。
与Dreambooth模型结合,它生成的穿中式婚礼礼服的歪国明星长这样。

它由360人工智能研究院提出,最近刚被AAAI接收,并已开源。

类似ControlNet的分支网络思路
文生图模型的中文原生问题,一直是一个重点研究问题。
受算力和数据因素的限制,国内大量的中文AI绘画产品背后,实际上很多是以开源的英文模型及其微调模型为能力基座,但是,英文模型包括且不限于SD1.4/1.5/2.1/3.5以及DALLE、Midjourney、Flux等,因为这些模型的训练数据以英文数据为主,因此在生成图像时,主体形象包括人物、物品、建筑、车辆、服饰、标志等,都存在非常普遍和明显的英文世界观偏见。
BDM是我们在多模态生成方向比较早期的工作,关注两个关键问题:
1)原生中文及生成模型的世界观偏见2)与SD生态的兼容性
冷大炜博士对BDM工作的主要着眼点做了如上的精炼概括。
“原生中文”问题指的不仅仅是文生图模型支持中文输入,更核心的是要求模型生成的人、物形象应该符合中文文化的认知。
下图是AI绘画模型的世界观偏见实例,从左到右分别是SDXL,Midjourney,国内友商B*,国内友商V*:

中文AI绘画模型,从实现的路线选择上,从易到难大致有以下几种方式:
英文模型 + 翻译。
简单直接,除了翻译外几无成本。这种方式只能解决表面上的中文输入问题,并不能解决英文模型因为模型偏见而无法生成符合中文文化认知形象的问题。
英文模型 + 隐式翻译。
与显式调用翻译服务不同,这种方式是将英文模型的text encoder替换为中文text encoder,并利用中英文平行语料对中文text encoder进行训练,使其输出的embedding空间与原来的英文text encoder对齐。本质上属于一种隐式翻译,也是成本非常低的一种方案,同样无法解决模型的世界观偏见问题。
英文模型 + 隐式翻译 + 微调。
在上面方法基础上,将对齐了text encoder的模型使用中文图文数据进一步整体微调以提升模型对中文形象的输出能力。可以在一定程度上缓解英文基底模型带来的模型偏见问题。
中文数据从头训练。
这是最彻底的一种中文化方案:理解中文输入,并能给出符合中文文化认知的图像输出结果,可以完美解决模型的世界观偏见问题。
上述四种路线,第4种路线看上去非常完美,但仍有一点值得额外的研发努力:在基座模型之外,我们需要进一步考虑的是大模型时代的模型生态问题。
围绕着以SD为代表的开源模型,已形成了非常庞大的开源社区生态,这个生态中大量衍生风格模型、插件模型等积累了非常宝贵的群体智力资产。
在克服AI绘画模型世界观偏见的基础上,进一步实现对开源社区的兼容,就是我们的BDM工作所要解决的第二个关键问题。
BDM从模型结构上是一种类似ControlNet的分支网络思路,以不同的网络分支学习不同语言的数据,因此从原理上BDM不仅可以实现原生中文图像生成,也可以实现任意X语言的图像生成,并保证生成的图像符合对应语言文化的认知。
英文部分可以直接复用已有的开源模型,从而实现与开源社区的无缝兼容。注意BDM在使用时只需要输入一种语言,比如输入中文时,英文分支是以空文本作为输入的。
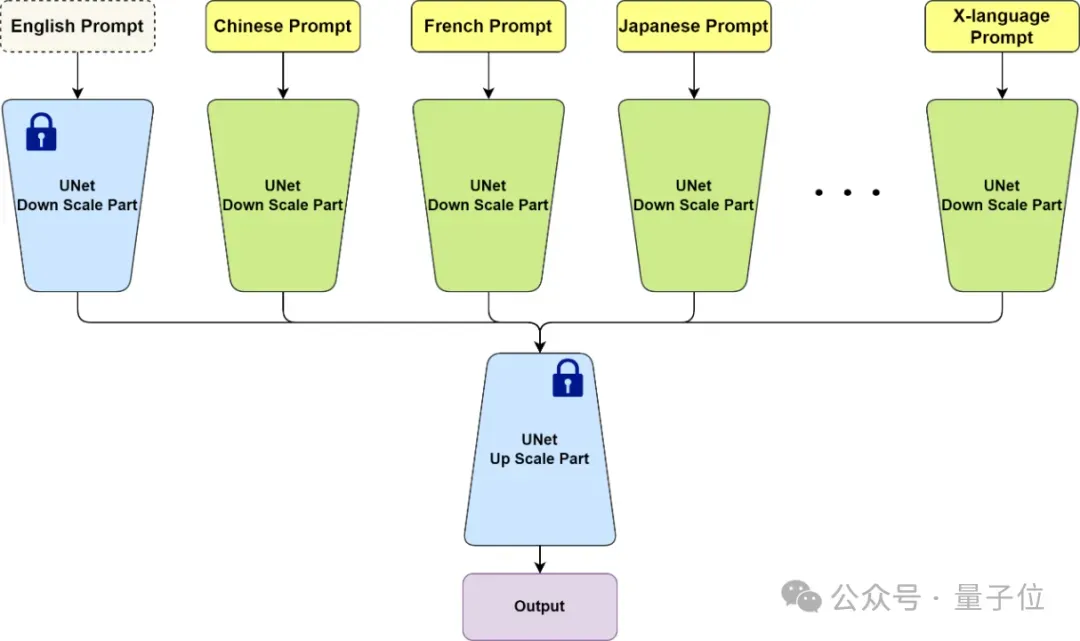
BDM v1版本使用10亿量级的中文图文数据进行训练,并兼容SD1.5社区生态。
下图展示了BDM在生成中文特有概念的能力和翻译无法应对的中英多义情况下的生成效果:

下图则展示了BDM在SD1.5社区生态兼容性上的情况,可以看到BDM对不同的SD1.5风格微调模型具有很好的兼容性,特别是BDM同时保持了中文形象的输出能力,更多案例请详见AAAI论文。

关于360人工智能研究院
在360集团All in AI的大背景下,360人工智能研究院发挥自身的智力优势,承担多模态理解和多模态生成大模型(俗称图生文和文生图)的战略研发任务,并在两个方向上持续发力,陆续研发了360VL多模态大模型,BDM文生图模型,可控布局HiCo模型,以及新一代DiT架构Qihoo-T2X等一系列工作。
近日,研究院在多模态理解方向的工作IAA和在多模态生成方向的工作BDM分别被AI领域的top会议AAAI接收,这两项工作的研发负责人为冷大炜博士。
据悉本届AAAI 2025会议收到近1.3万份投稿,接收3032份工作,接收率仅为23.4%。
Arxiv: https://arxiv.org/abs/2309.00952Github: https://github.com/360CVGroup/Bridge_Diffusion_Model