在计算机视觉领域,图像分割是一项核心任务,广泛应用于目标识别、追踪和分析等多个场景。本文将介绍一种新颖的方法,利用两个基于变换器模型的零样本图像分割技术:GroundingDINO负责目标检测,而单任务注意力模型(SAM)负责语义分割。我们将详细解读代码,并解释涉及的关键概念。现在,让我们先来了解一些重要的术语!

Grounding DINO与SAM的结合
1. 变换器模型
这类神经网络架构在自然语言处理领域取得了革命性的进展,如翻译、摘要和文本生成等任务。它们通过多层处理输入序列(例如单词或字符),并通过注意力机制关注输入的不同部分。设想一个翻译者使用变换器模型将英文句子翻译成其他语言。在翻译“the quick brown fox”时,模型可能会先关注“the”,然后是“quick”,逐步将信息整合进翻译中。
变换器模型的设计使其能够有效处理长距离依赖问题,并实现并行计算,这使得它们在处理序列数据时表现出色。在本文中,我们将应用GroundingDINO和SAM这两个变换器模型。
2. 目标检测与语义分割
这是计算机视觉中的两个基础任务。目标检测通过边界框定位图像中的目标对象,而语义分割则为图像中的每个像素分配类别标签。目标检测提供了对象的位置信息,语义分割则提供了对象与背景的详细分割。

3. 零样本学习
这是一种机器学习技术,允许模型在未针对特定任务进行训练的情况下执行任务。模型通过利用其他相关任务的知识来执行新任务。在本文中,我们将利用零样本学习技术,根据用户提供的文本标签描述来分割图像中的对象,即使模型未曾针对这些标签进行过训练。
可以通过https://colab.research.google.com/访问Google Colab编写代码:
复制
#app.py
!pip install spaces
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
import torch
from transformers import SamModel, SamProcessor
import spaces
import numpy as np
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sam_model = SamModel.from_pretrained("facebook/sam-vit-base").to("cuda")
sam_processor = SamProcessor.from_pretrained("facebook/sam-vit-base")
model_id = "IDEA-Research/grounding-dino-base"
dino_processor = AutoProcessor.from_pretrained(model_id)
dino_model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
def infer_dino(img, text_queries, score_threshold):
queries=""
for query in text_queries:
queries += f"{query}. "
width, height = img.shape[:2]
target_sizes=[(width, height)]
inputs = dino_processor(text=queries, images=img, return_tensors="pt").to(device)
with torch.no_grad():
outputs = dino_model(**inputs)
outputs.logits = outputs.logits.cpu()
outputs.pred_boxes = outputs.pred_boxes.cpu()
results = dino_processor.post_process_grounded_object_detection(outputs=outputs, input_ids=inputs.input_ids,
box_threshold=score_threshold,
target_sizes=target_sizes)
return results
@spaces.GPU
def query_image(img, text_queries, dino_threshold):
text_queries = text_queries
text_queries = text_queries.split(",")
dino_output = infer_dino(img, text_queries, dino_threshold)
result_labels=[]
for pred in dino_output:
boxes = pred["boxes"].cpu()
scores = pred["scores"].cpu()
labels = pred["labels"]
box = [torch.round(pred["boxes"][0], decimals=2), torch.round(pred["boxes"][1], decimals=2),
torch.round(pred["boxes"][2], decimals=2), torch.round(pred["boxes"][3], decimals=2)]
for box, score, label in zip(boxes, scores, labels):
if label != "":
inputs = sam_processor(
img,
input_boxes=[[[box]]],
return_tensors="pt"
).to("cuda")
with torch.no_grad():
outputs = sam_model(**inputs)
mask = sam_processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(),
inputs["original_sizes"].cpu(),
inputs["reshaped_input_sizes"].cpu()
)[0][0][0].numpy()
mask = mask[np.newaxis, ...]
result_labels.append((mask, label))
return img, result_labels
import gradio as gr
description = "This Space combines [GroundingDINO](https://huggingface.co/IDEA-Research/grounding-dino-base), a bleeding-edge zero-shot object detection model with [SAM](https://huggingface.co/facebook/sam-vit-base), the state-of-the-art mask generation model. SAM normally doesn't accept text input. Combining SAM with OWLv2 makes SAM text promptable. Try the example or input an image and comma separated candidate labels to segment."
demo = gr.Interface(
query_image,
inputs=[gr.Image(label="Image Input"), gr.Textbox(label = "Candidate Labels"), gr.Slider(0, 1, value=0.05, label="Confidence Threshold for GroundingDINO")],
outputs="annotatedimage",
title="GroundingDINO 🤝 SAM for Zero-shot Segmentation",
description=description,
examples=[
["./cats.png", "cat, fishnet", 0.16],["./bee.jpg", "bee, flower", 0.16]
],
)
demo.launch(debug=True)代码解析:
(1) 代码首先通过pip安装必要的包,并导入所需的库,包括PyTorch、GroundingDINO、SAM和Gradio。
(2) GroundingDINO是一个基于变换器的目标检测模型。它可以根据图像和文本描述输出与描述相对应的对象的边界框。在本代码中,我们利用GroundingDINO根据用户指定的文本标签来定位图像中的对象。
(3) 单任务注意力模型(SAM)是另一个基于变换器的模型,用于图像到图像的翻译任务,如语义分割。SAM模型可以根据图像和文本描述生成与描述中对象相对应的分割掩码。在本文中,我们将使用SAM根据GroundingDINO提供的边界框进行对象的语义分割。
(4) 代码根据可用性设置运行代码的设备(GPU或CPU)。
(5) 加载SAM模型和GroundingDINO模型,并将它们的处理器转移到GPU以加快计算速度。
(6) infer_dino()函数接受图像、文本查询(候选标签)和置信度阈值作为输入,并使用GroundingDINO模型处理输入,识别具有边界框的对象检测。
(7) query_image()函数用@spaces.GPU装饰器装饰,表示它将在GPU上运行。这个函数接受图像、文本查询和置信度阈值作为输入。
(8) query_image()首先将文本查询分割成单独的标签,并将其传递给infer_dino()函数以获取对象检测和边界框。
(9) 对于每个对象检测,它使用SAM模型生成掩码,即将对象的边界框传递给SAM模型,并为每个对象生成一个掩码。
(10) 最后,函数返回带有生成的掩码和相应标签的图像。
(11) 代码定义了一个Gradio演示,接受图像、候选标签和置信度阈值作为输入,并返回带有生成的掩码和标签的注释图像,同时提供示例输入以供演示。
(12) 启动Gradio演示,并显示用户界面。
运行代码后,我们将获得Gradio空间链接:
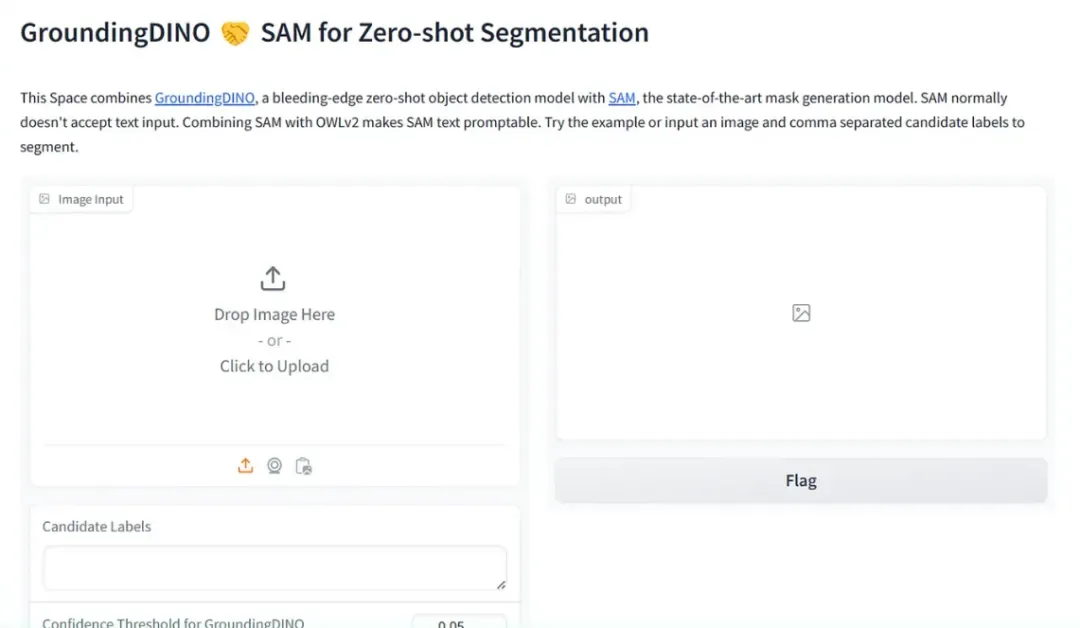
结果展示(红色涂抹)

完整代码:https://github.com/jyotidabass/GroundingSAM-Gradio-App/blob/main/GroundingSAM.ipynb